The idea of combining peer-to-peer distribution (torrents) with source control (git) has recently been promoted (GitTorrent-2015-Announcement) but it actually has been around for awhile (GitTorrent-GoogleCode).
The appeal for this amalgamation is the combining distributing software products (packages, ISOs, etc.) via torrents while keeping all the benefits of source control systems such as Git.
The conflict between the ideas is fairly obvious. Torrents are not viewed as providing reliable service for the fundamental reason that they are not reliable. They optimize crowd distribution of popular material. Git needs to retain historic boring archives of old versions which will probably never be fetched.
There are several inherent contradictions between the “Git” and “Torrent” worlds:
- Source Control takes responsibility for retention of every version of an object, forever.
- Peer-to-peer networking is dependent on a social control which assumes that there is demand to access the content being shared. It is easy for a peer-to-peer network to identify and shame “leaches” who only download material but never donate bandwidth to the community. Measuring who is actually retaining seldom retrieved versions would be far harder.
- A primary feature of source control systems is to attribute every byte of the current version of a file/object to the specific update when it was introduced, and who to “blame” for that update. Source control systems frequently reqiure each edit to be password and/or certificate authenticated. Torrents which required tracable attribution for every contribution would see a major portion of their seeders unwilling to “contribute” material. The MPAA would probably claim that this is most of the content being torrented.
However, there are some major architectural similarities between Object Storage solutions designed for Enterprise storage (whether in-house and/or cloud-based) and peer-to-peer networking:
- Both rely on a large number of storage targets rather than upon high availability of specific storage targets. Many low-cost modestly-available targets end up being cheaper and more reliable than a few highly available targets. But peer-to-peer targets don’t just “fail”, they are withdrawn from availability by their owners. That is a problem that Enterprise storage does not have to address.
- Both benefit from the use of cryptographic hashes to identify chunks. Software distribution has been publishing checksums of packages and ISOs for some time, but they are typically maintained separately from the storage. This is unforntate because it requires the end user to remember to apply the fingerprint to the downloaded content, something that is probably actually done several times a day.
Actually peer-to-peer networks are more in need of cryptographic hashes than Enterprise storage clusters, but so far they tend to use cheaper hash algorithms. Every contributing sever cannot be vetted by the peer-to-peer network. Volunteer help seldom sticks around for along validation process. Therefore peer-to-peer networking must be designed to prevent malevolent and/or misbehaving servers from corrupting the distributed storage cluster.
Directories?
One of the interesting statements that Chris Ball made in his blog announcement of the 2015 vintage GitTorrent was that FTP was unsuitable as a distribution method because there’s no master index of which hosts have which files in FTP, so we wouldn’t know where to look for anything.
But BitTorrent style directories are not the real solution either. They are the equivalent of HDFS or pNFS – centralized metadata referencing distributed chunks/blocks.
When you fully embrace identifying chunks with Cryptographic Hashes you just have to go all the way (which is what we did with NexentaEdge). Everything needs to be a chunk identified by a cryptographic hash of its payload. That includes the metadata. You just have to name some of the metadata chunks to anchor the references to the other chunks.
The root metadata chunks need to have an additional lookup driven by the cryptographic hash of their fully qualified name. To make a globally unique name just scope it by a domain name.
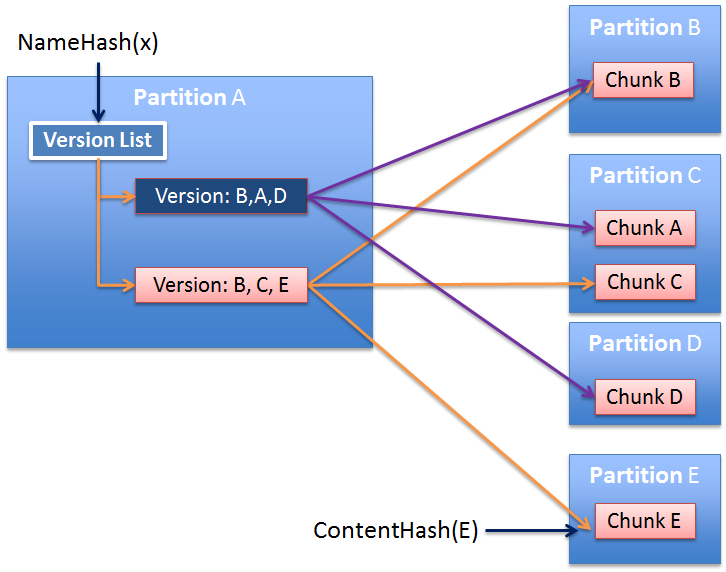
The Name Hash of a fully qualified, domain name scoped, object identifier needs to be able to find a list of the versions of the named object.
Each chunk is either considered to be “named” or “unnamed”. Named chunks are located by their Name Hash. Unnamed chunks by the Content Hash. Whichever hash is selected yields some form of partition of the global namespace. For example the configuration might specify that there are 1024 partitions. You then query for the desired hash on servers registered to support that partition.
To find the Metadata for an object:
- Hash the fully qualified name of the object.
- Map the hash value to a partition.
- Ask the servers supporting that partition to return the most recent version of the Manifest for this object, or refer you to a later version that they know about but do not have a copy of.
- Note that the returned Manifest still has a cryptographic hash of its content, allowing end-to-end validation of the manifest.
- Pick the most recent valid version returned.
Then used the saved content hashes in the Manifest to find the payload chunks.
- Map the content hash to its partition.
- Ask the servers supporting that partition to return this chunk, or to refer you to another server that has it.
- Only the first replica found actually found needs to be returned.
Note: this is slightly different from what NexentaEdge does, but NexentaEdge has the benefit of having all of the storage servers for a given cluster being at a single location. This enables use of multicast messaging to query all members of a “partition” in a single operation. There isno way to use multicast reliably over wide area networks.
In the following diagram various payload chunks are put to various partitions. Their content hashes are saved, and then referenced in version manifests which are stored (and indexed) on the partition derived from the name hash of the object name.

Object Storage Features Applied to Peer-to-Peer Networking
Despite the inherent conflicts there are several features of enterprise object storage that are applicable to the problem of peer-to-peer storage.
In both Enterprise and peer-to-peer storage, objects can be broken down into chunks Identified by a Cryptographic Hash. Each chunk represents a portion of an Object Version’s payload or metadata. Payload chunks can be identified by a cryptographic hash of their payload. Metadata chunks can be also identified by a cryptographic hash of their payload, but also need to be found using only the object name. This can be done using the cryptographic hash of the object’s fully qualified name.
Using cryptographic hashes to identify chunks has several benefits.
- Cryptographic Hashes Self-Validate the Chunk. As each chunk is retrieved the client can validate that it’s payload is compatible with its cryptographic hash.
- Cryptographic Hashes enable distributed deduplication.
- Cryptographic Hashes can drive the distribution of Chunks. The cryptographic hash of the content and/or name can determine which storage targets hold each chunk.
Breaking up Storage
Distributing chunks by cryptographic hashes allows each peer-to-peer server to only deal with a subset of the objects in the system.
A client looking for a peer-to-peer replica of a chunk only need to contact the set of server dealing with the desired slice of the “hash space”. This applies whether seeking metadata or payload.
Authenticating Users
In enterprise object storage systems, users typically authenticate using a tenant-specific authorization server, such as Active Directory or LDAP.
For peer-to-peer storage a given domain name would publish a public key. The holder of the matching private key could either retain the exclusive right to make new versions or just the right to delete posts made by others.
The system should probably also require each version be signed with a key associated with the email address.
Remaining Issues
One of the toughest challenges for anyone building a peer-to-peer storage network is determining how many replicas (or erasure encoded slices) are needed to make the chance of losing content to be effectively zero (or some other TBD threshold).
This is related to the other challenge of how to encourage users to provide storage.
The costs of long-haul communications are such that a peer-to-peer storage network is unlikely to be cost effective on a $$$ per IOP or TB basis. But there are other benefits of a peer-to-peer storage community that may be appealing:
- There is no need to tell anyone other than your end users what your are storing. Metadata can be encrypted. If you know the key you can decrypt the metadata and confirm the name and version of the version metadata retrieved. If you do not know the key, you have a blob with a name that hashes to X.
- Content Distribution (albeit a distributed mirroring system may be more valuable here). Those fetching from a mirror do not have to independtly validate the content, corrupted or altered data cannot be retrieved from the system.
- There is another, related to dynamic ingest of data, which we’ll cover in my next blog.
Disclaimer
This post touches upon features of Nexenta’s object storage product NexentaEdge. Portions of NexentaEdge are covered by patent applications and/or patents. Nexenta reserves all rights under those patents.