So tell me, what do you truly desire?
Lucifer Morningstar
Introduction
AIStore (or AIS) has been in development for more than three years so far and has accumulated a fairly long list of capabilities, all duly noted via release notes on the corresponding GitHub pages. At this stage, AIS meets common expectations to a storage solution – its usability, manageability, data protection, scalability and performance.
AIStore is a highly available partition-tolerant distributed system with n-way mirroring, erasure coding, and read-after-write consistency(*). But it is not purely – or not only – a storage system: it’ll shuffle user datasets and run custom extract-transform-load workloads. From its very inception, the idea was to provide an open-source, open-format software stack for AI apps – an ambitious undertaking that required incremental evolution via multiple internal releases and continuous refactoring…
AIS is lightweight, fully reliable storage that can be ad-hoc deployed, with or without Kubernetes, anywhere from a single Linux machine to a bare-metal cluster of any size. Prerequisites boil down to having a Linux and a disk. Getting started with AIS will take only a few minutes and can be done either by running a prebuilt all-in-one docker image or directly from the source.
AIS provides S3 and native APIs and can be deployed as fast storage (or a fast on-demand cache) in front of the 5 (five) supported backends (whereby AIS itself would be the number 6, respectively):

Review
The focus on training apps and associated workloads results in a different set of optimization priorities and a different set of inevitable tradeoffs. Unlike most distributed storage systems, AIS does not break objects into uniform pieces – blocks, chunks, or fragments – with the corresponding metadata manifests stored separately (and with an elaborate datapath to manage all of the above and reassemble distributed pieces within each read request, which is also why the resulting latency is usually bounded by the slowest link in the corresponding flow chart).
Instead, AIS supports direct (compute <=> disk) I/O flows with the further focus on (re)sharding datasets prior to any workload that actually must perform – model training in the first place. The idea was to make a system that can easily run massive-parallel jobs converting small original files and/or existing shards to preferred sharded formats that the apps in question can readily and optimally consume. The result – linear scalability under random-read workloads, as in:
total-throughput = N * single-disk-throughput
where N is the total number of clustered disks.
It is difficult to talk about a storage solution and not say a few words about actual I/O flows. Here’s a high-level READ diagram, which however does not show checksumming, self-healing, versioning, and scenarios (that also include operation in the presence of nodes and disks being added or removed):
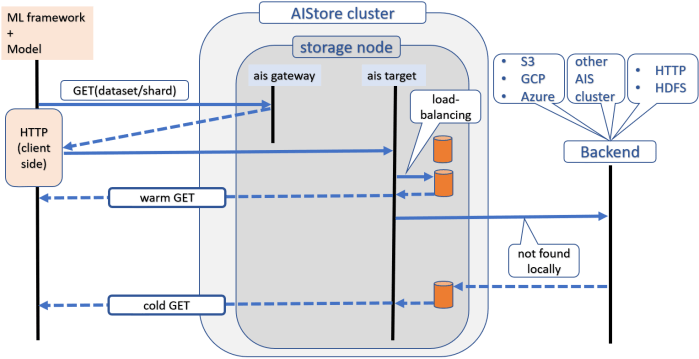
Further
You can always start small. As long as there’s HTTP connectivity, AIS clusters can see and operate on each other’s datasets. One can, therefore, start with a single all-in-one container or a single (virtual) machine – one cluster, one deployment at a time. The resulting global namespace is easily extensible via Cloud buckets and other supported backends. Paraphrasing the epigraph, the true desire is to run on commodity Linux servers, perform close-to-data user-defined transforms, and, of course, radically simplify training models at any scale.
