BIER
As noted in my previous blog on Transactional Subset Multicasting a distributed object cluster greatly benefits from push-mode multicasting. The sender determines the set of recipients rather than the recipients joining a group. Having the listeners join the multicast group adds a round-trip delay to every join. For a distributed storage cluster a dynamic group would have to be formed for each chunk put. That would typically be every 128 KB to 2 MB. That would be expensive even if IGMP/MLD joins executed promptly. They do not.
The only thing that is slower than IGMP/MLD joins are IGMP/MLD leaves. There is only minimal harm in not instantly shutting off an end stations reception of a stream it has lost interest in. But when you are trying to manage exactly which packets are delivered via which edge links you need the Leaves to process just as quickly as the Joins.
So naturally I was very interested in BIER. The NexentaEdge application more needs a short list of destinations, but a bitmap can be fairly efficient. BIER can even narrow the mapping to a “sub-domain” or a subset of a sub-domain’s bitmap using a “Subset Identifier” (SI). The bottom line is that each Negotiating Group could be mapped to a 64-bit bitmap. A single 64-bit map is shorter than a list of IPV6 addresses, so header space would not have been a problem.
Not That Straight Forward
While BIER looked like an interesting alternate solution to push multicasting I kept getting confused reading the BIER drafts. They seemed amazingly tolerant of inefficient forwarding algorithms. More importantly there was no effort to map BIER forwarding to the currently deployed L2 forwarding tables used by typical current generation switches.
I was particularly intrigued by the BIER-TE (BIER-Traffic Engineering) draft. It seeks to optimize the end-to-end packet flows by adding extra bits for use by intermediate routers. Basically, ingress routers would determine what paths that intermediate routers should use for this packet and set extra bit positions accordingly. The intermediate routers do not need to understand topology, just which bit position represent its links. The draft also cleverly identifies several cases where the same bit position can be safely used for multiple non-conflicting purposes. This avoids exploding the bitmap size needed.
The assumption here is that the intermediate forwarders could not possibly be expected to know the forwarding path for each bit. Each Edge switch/router only has to know the forwarding required for the applications that are relevant to the nodes on that edge switch. A core switch/router would have to know the forwarding for every application.
This line of thinking is nearly the opposite of the thinking for distributed storage clusters. The Replicast transport protocol assumes a non-blocking, no-drop core. It then worries about how to load-balance the deliveries to edge links and how to fully utilize those links without ever over-subscribing them. The goal is balancing traffic at the edge of the cluster. The core takes care of itself.
In the following illustration some of the edge nodes are shown connected to the Edge switch on the bottom right. There would actually be more Edge nodes, and they would be attached to every Every switch.

With this type of network, Replicast does not need to optimize switch-to=-switch traffic at all. If a packet has non-local destinations it could be flooded out of every port to reach all other switches. As long as those switches did not loop the packet, or deliver it to any non-addressed edge port, everything will be fine. A non-blocking core has the capacity to deliver the frame to every edge switch, so delivering packets to a subset when the targeted set of ports does not happen to include every edge switch is nice but not necessary to make the network work.
To traditional multicasting ears this is crazy talk. They hear “Who cares if I send the packet 500 miles to a city where it was not needed, I didn’t deliver it the last five yards.”
But in a Replicast network it is exactly the last five yards that are in danger of being flooded.
The traditional multicast concern deals with this type of network topology:
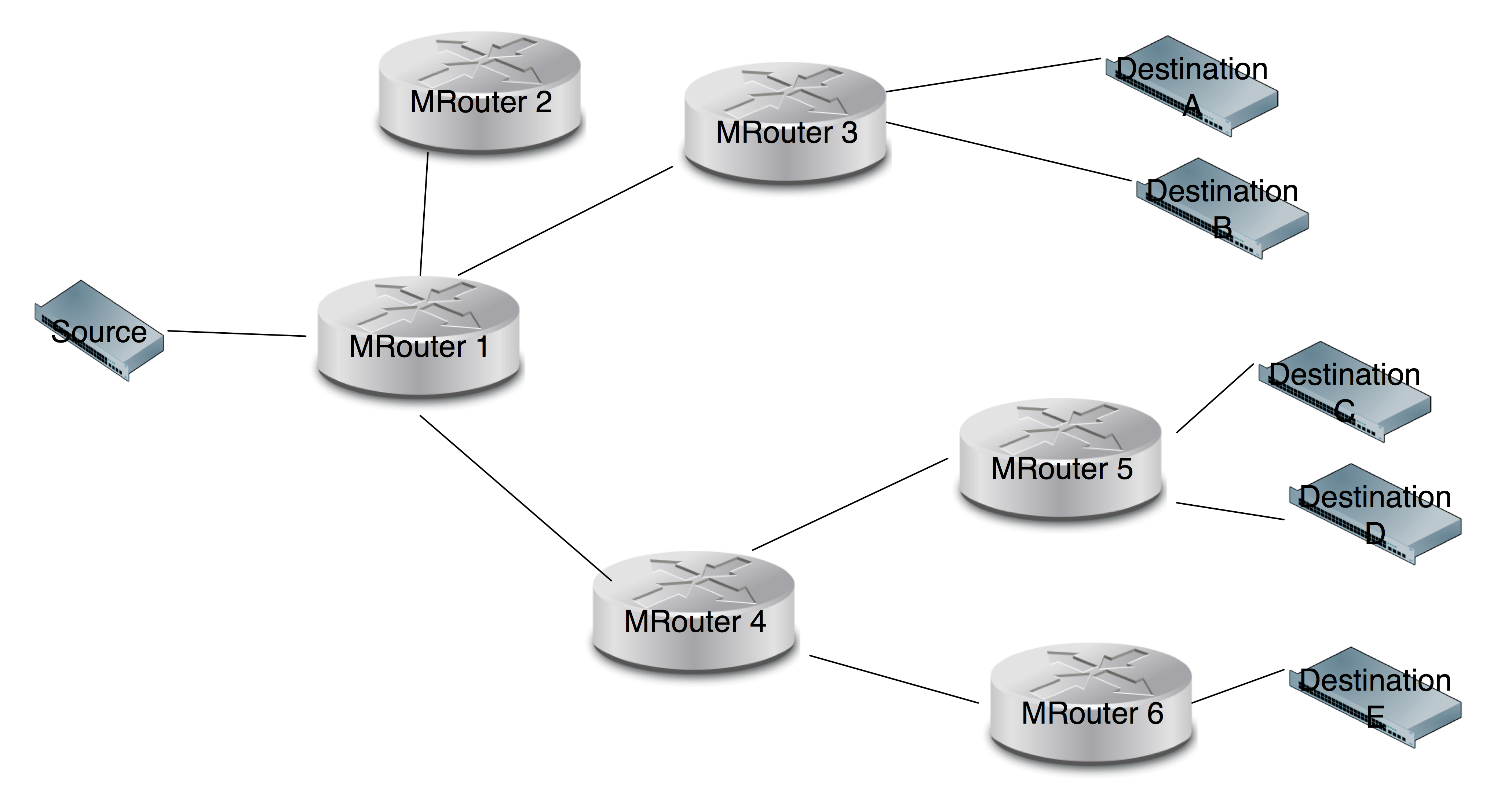
In the above diagram the Source wants to multicast packets to Destinations A,B,C,D and E. This implies the following packet relays:
- Source –> MRouter 1 –> MRouter 3 –> Destination A
- MRouter 3 –> Destination B
- MRouter 1 –> Mrouter 4 –> MRouter 5 –> Destination C
- MRouter 5 –: Destination D
- MRouter 4 –> MRouter 5 –> Destination E.
Specifically, the packet is only relayed from MRouter 1 to MRouter 4 once (and from MRouter 1 to MRouter 3 once). It is not relayed form MRouter 1 to MRouter 2.
When this is your concern, having the target MRouter flood the packet locally is undesirable (or unicast delivery it N times), but certainly not the end of the world. Tuhe hard work was getting it to the very small subset of edge MRouters that had subscribers.
Totally divergent goals, but the same protocol seems applicable to both problems. This is what you want to see in a good protocol.
How are Users Supposed to Set These Extra Bits? Who are Users?
I was still troubled by some gaps that looked just glaring to me in the BIER-Traffic Engineering proposal. Exactly what would an application be expected to understand when it filled out this bitmap? Where was its source of information for this extended bitmap? Who was responsible for setting which bits? How were they supposed to map a desired destination IP address to one or more bit positions? How long would a mapping remain valid?
So I asked on the mailing list, and got a very surprising answer (https://mailarchive.ietf.org/arch/msg/bier/GM-Aqpvmlul-E8vbJR8qrCTJcNs)
On Fri, Oct 16, 2015 at 02:47:33PM -0700, Caitlin Bestler wrote: > I think I'm understanding BIER-TE finally, but I have a few questions to > confirm my understanding. > > How does an application use this? > > In particular, how is this done so the overhead of determining the > end-to-end path is not > imposed on the host or BFIR on a per packet basis? I don't think we've done a lot of brainstorming how to do end-2-end BIER where the two ends are actual applications instead of transport services gateways, eg: BIER-PE or the like (encap/decap native IP multicast or MPLS multicast).
This was an eye-opener.
It was now clear to me that I was viewing the whole issue of multicast optimization from a very different perspective than everyone else:
- I was trying to optimize traffic on the edge links. Everyone else was optimizing the router-to-router links.
- I was primarily thinking of L2 subnets, routers could exist but they were the exception. Everyone else was think of the routers and only incidentally of L2 delivery.
- I was thinking that one bit represented an end station. Everyone else was thinking that it was an edge router.
Amazingly the entire infrastructure fits either mode of thinking. If you view each end station as being its own BIER then everything in the architecture document is fully applicable to end-station delivery.
The only exception is that the forwarding pseudo-code does not explicitly include a step for using a single L2 multicast delivery to reach N local destinations. But that is certainly consistent with the intent, as that it explicitly states that when forwarding router to router that you should only send a single BIER packet down any one port.
I’m now convinced that I can combine BIER with Transactional Subset Multicasting. When a BIER forwarder sees the desirability of a multicast address existing, and when it has a unused transactional subset multicast address available it will:
- Unicast deliver the current packet to each of the ports.
- Configure the transactional multicast address to reach that set of local ports. The reference multicast address is the entire BIER sub-domain or s specific SI-selected slice of it.
- Use the transactional subset multicast address for subsequent packets until the forwarding rule is aged out or superseded by a newer set that needs the multicast address.

