It is a conventional wisdom: peer-to-peer storage works for distributing of popular items. A torrent swarm is never more efficient than when delivering the latest episode of Game of Thrones.
But there is another usage of peer-to-peer networking that is almost the opposite – inbound swarming. This idea was originally suggested by Robert Novak while he was at Nexenta, but many details have been flushed out since then. An inbound swarm is quite unlike a Game of Thrones swarm: it carries a horde of distinct files that are bound to only one destination, and most will never be accessed.
Turning Peer-to-Peer Inside-Out
The use-case is simple: imagine that you have a very large number of people generating content at a location with limited upstream capacity. The “limited” capacity can be quite high, it just has to be limited relative to the demand.
If the use case is not clear, consider a technical conference at the Moscone Center (or any venue). Or consider a sporting event that wasn’t built with a WIFI router for each row of seat. In either case you have a lot of content being generated by smartphones and tablets, a lot more content than can be transmitted live from the venue.
This content has some special characteristics:
- It is undoubtedly targeted to some form of object storage: a photo archive site, a cloud storage folder or perhaps even a home server.
- 99.9% of it will reach its destination without any need for peer-to-peer networking, eventually. Specifically when the smartphone or tablet returns to the office or home it will upload everything via WiFi without any real problems.
- It needs to be backed up. This content is at risk of failure, either of the smartphone/tablet or of the SD card that the content is stored on.
Peer-to-peer networking can provide a backup service to these mobile devices tailored exactly to these scenarios.
Basically, the mobile devices back each other up. But this needs to be automatic, between collaborating users without relying on negotiating trust on an individual basis.
To establish this trust the application would have to:
- Throttle the amount of storage and bandwidth each volunteer provided. This is a feature of torrenting software already.
- Promise the source of the material that nobody would be able to view or alter the content before it reached its final destination.
- Promise the intermediate holders of the data that they could in no way be held responsible for any of the content because there was absolutely no way for them to review it.
Once the trust issues are solved there is more than enough bandwidth within a Conference center, and more than enough storage for all the content being generated. Content just needs to be held on multiple devices until the bandwidth is available to deliver the blob to its ultimate destination.
Each file/object is:
- Encrypted. The payload is completely undecipherable until it reaches its destination.
- Fingerprinted. There is a unique id for each file/object calculated by a cryptographic hash of the file/object content.
This serves several purposes:
- It prevents unauthorized alteration of the content by any of the volunteer devices holding a backup of it.
- It allows easy detection of when the original device or a different backup device has already delivered the file/object. It is likely that if such a service were deployed that the typical file/object would never be accessed. Most of the time the original device will make it safely back to the office or home and deliver the file itself. Like any backup image, the preferred scenario is that it is never accessed.
- The designated destination could even be an intermediate destination to provide greater anonymity. The first destination would decrypt the object enough to know where it would should route it to. This doesn’t have to be NSA-proof obfuscation; but most people would rather not be broadcasting their Google Photo account identification to everyone at the venue with them
Pieces of this solution have been around for a long time. Routing schemes exist for ad hoc networks that are dynamically discovered. Store and forward relay is as old as email. But this solution is actually far simpler than either of those. Each replica is stored on at most one intermediate device, and is forwarded at most once. The only ad hoc network used is at the source venue. Forwarding would be limited to known “home” Wi-Fi networks that are connected to the Internet.
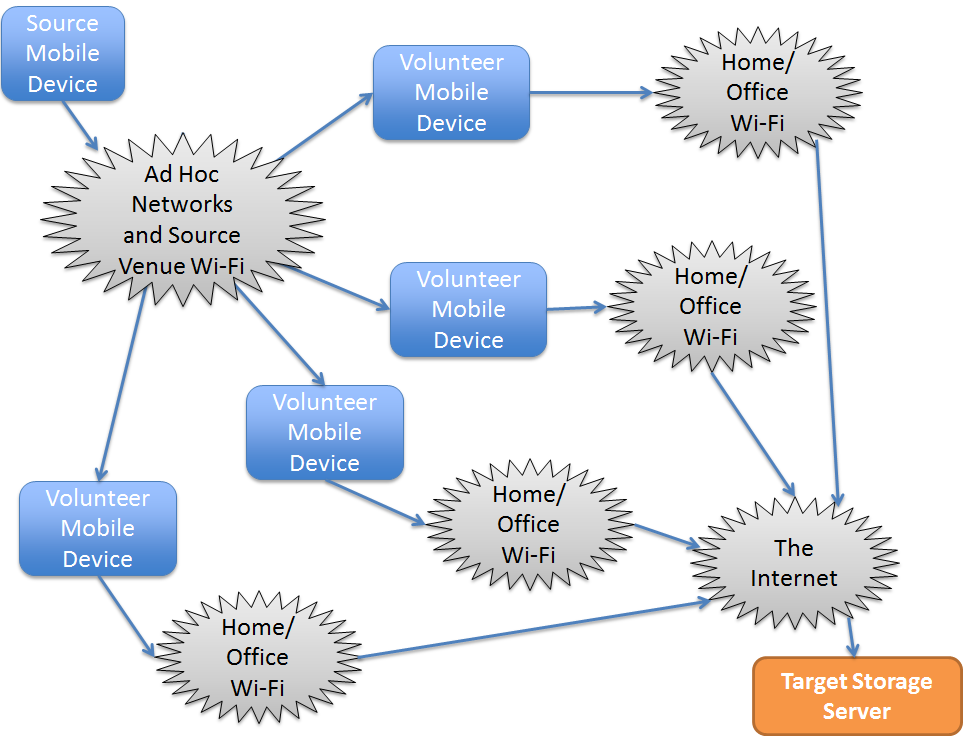
Crowd-Sourced Backup
So this is essentially a mobile “crowd-sourced” backup system that is specifically tailored to the needs of files generated by mobile devices, such as photos of presentations at a conference, or photos of friends together at a convert, etc.
The goal is to provide backup replicas that are retained for perhaps half a day. There is no need for long term storage. Rather than seeking to distribute replicas to many destinations, it instead seeks many paths to a single destination per object.
The biggest gotcha with this idea is that it really takes a Mobile OS vendor to properly enable the on-site file transfers. There isn’t any incentive for users to download a “CrowdSharing” app unless they are likely to encounter other devices with the same App installed.
Without critical mass this doesn’t work. Do you remember the Zune’s Wireless Sharing feature? It would have been a big plus, if you ever ran across other people with Zune’s to share with.
So this is a great potential application, but realistically it probably will not go anywhere unless embraced by Google and/or Apple.
