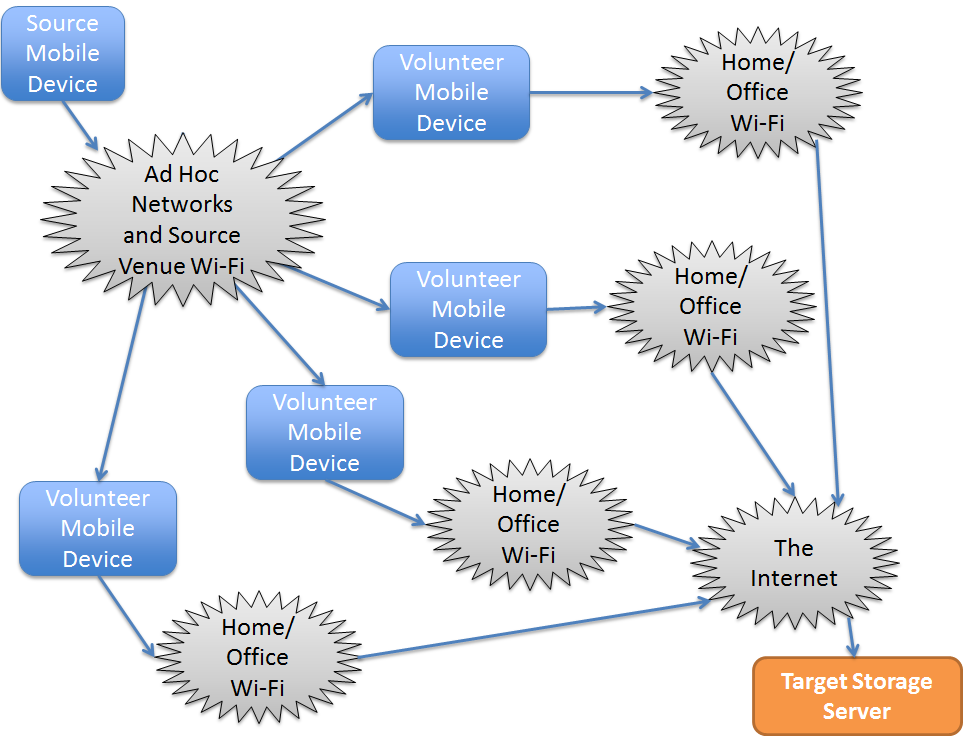
When it comes to ad-hoc wireless (mesh) networks, we probably visualize something like this:

The picture is a youtube screen grab; the video itself introduces the project SPAN (github: https://github.com/ProjectSPAN) to “enable communications in challenged environments”. Wikipedia has a somewhat better picture though, covering all kinds of wireless scenarios, including satellite.
Introduction
Wireless ad hoc networks go back 40 plus years, to the early 1970s (DARPA) projects, with the 3rd generation taking place in the mid-1990s with advent of 802.11 standards and 802.11 cards – as always, wikipedia compiles a good overview 1 2 3.
Clearly there’s a tremendous and yet untapped value in using cumulative growing power of smartphones to resolve complex tasks. There are daunting challenges as well: some common (security, battery life and limited capacity, to name a few), others – application specific. Separate grand puzzle is to monetizing it, making it work for users and future investors.
There’s one not very obvious thing that has happened though fairly recently, as far as this 40 plus year track. Today we know exactly how to build a scaleable distributed object storage system, system that can be deployed on pretty much anything, would be devoid of the infamous single-MDS bottleneck, load-balance on the backend, and always retain the 3 golden copies of each chunk of each object. Abstractions and underlying principles of this development can in fact be used for the ad hoc wireless applications.
I’ll repeat. Abstractions and principles that at the foundation of infinitely scaleable object storage system can be used for selected ad hoc wireless applications.
Three Basic Requirements
CrowdSharing (as in: crowdsourcing + file-sharing) is one distinct application (the “app”), one of several that can be figured out today.
The idea was discussed in our earlier blog and is a very narrow case of an ad hoc network. CrowdSharing boils down to uploading and downloading files and objects (henceforth “fobjects” 4, for shortness sake) whereby a neighbor’s smartphone may serve as an intermediate hop.
(On the picture above, Bob at the bottom left may be sending or receiving his fobject to Alice at the top left 5)
CrowdSharing by definition is performed on a best-effort basis, securely and optimally while at the same time preventing exponential flooding (step 1: Bob (fobject a) => Alice; step 2: Alice (fobject a, fobject b) => Bob; step 3: repeat), where the delays and jitters can count in minutes and even hours.
Generally, 3 basic things are required for any future ad hoc wireless app:
- must be ok with the ultimate connectionless nature of the transport protocol
- must manipulate fobjects [^4]
- must be supported by a (TBD) business model and infrastructure capable to provide enough incentives to both smartphone users and investors
Next 3 sections briefly expand on these points.
Connectionless
There’s a spectrum. On one side of it there are transport protocols that, prior to sending first byte of data, provision resources and state across every L2/L3 hop between two endpoints; the state is then being maintained throughout the lifetime of the corresponding flow aka connection. On the opposite side, messages just start flying without as little as a handshake.
Apps that will deploy (and sell) over ad hoc wireless must be totally happy with this other side: connectionless transports. Messages may take arbitrary routes which also implies that each message must be self-sufficient as far as its destination endpoint and the part of the resulting fobject it is encoding. Out-of-order or duplicated delivery must be treated not as an exception but as a typical sequence of events, a normal occurrence.
Eventually Consistent Fobjects
Fobjects 4 are everywhere. Photos and videos, .doc and .pdf files, Docker images and Ubuntu ISOs, log structured transaction logs and pieces of the log files that are fed into MapReduce analytics engines – these are all immutable fobjects.
What makes them look very different is an application-level, and in part, transactional semantics: ZFS snapshot would be an immediately consistent fobject, while, for instance, a video that you store on Amazon S3 only eventually consistent..
Ad hoc wireless requires eventual consistency 6 for the application-specific fobjects.
Business Model
On one hand, there are people that will pay for the best shot to deliver the data, especially in the situations when/where the service via a given service provider is patchy or erratic at best, if present at all.
On another, there is a growing smartphone power in the hands of people who would like to maybe make an extra buck by not necessarily becoming an Uber driver.
Hence, supply and demand forces that can start interacting via CrowdSharing application “channel”, thus giving rise to the new and not yet developed market space..
How that can work
Messages
On the left side of the diagram below there’s a fobject that Bob is about to upload. The fobject gets divided into chunks, with each chunk getting possibly sliced as well via Reed-Solomon or its derivatives. RSA (at least) 1024-bit key is used to encrypt those parts that are showed below in red and brown.
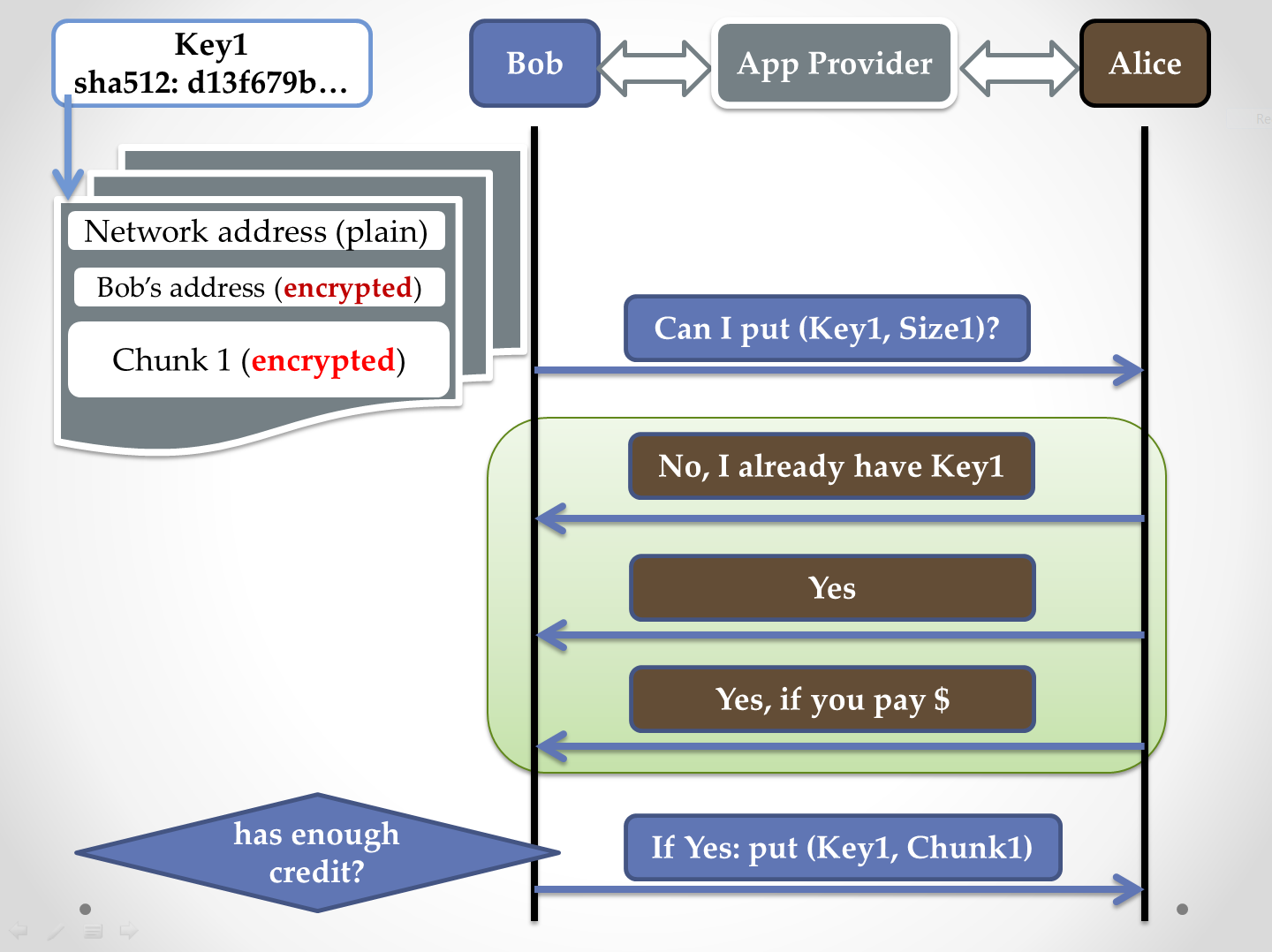
Each chunk or slice forms a self-sufficient message that can find its way into the destination object through unpredictable and not very reliable set of relays, including in this case Alice’s smartphone. Content of this message carries metadata and data, a simplified version of this is depicted above. Destination (network) address is the only part that is in plain text, Bob’s address, however, is encrypted with a key known to the service provider at the destination, while the content itself may be encrypted with the different key that the provider does not have.
The entire message is then associated with its sha512 content digest that simultaneously serves as a checksum and a global (and globally unique) de-duplicator.
Actors
The diagram shows 3 “actors”: Bob – uploads his fobject; Alice – provides her smartphone’s resources and maybe her own home network (or other network) to forward Bob’s object to the specified destination.
And finally, Application Provider aka Control Center.
The latter can be made optional; it can and must serve though to perform a number of key functions:
- maintain user profiles and their (user) ratings based on the typical like/dislike and trust/distrust feedback provided by the users themselves
- record the start/end, properties and GPS coordinates of each transaction – the latter can become yet another powerful tool to establish end-to-end security and authenticity (and maybe I will talk about it in the next blog)
- take actual active part during the transaction itself, as indicated on the diagram and explained below, and in particular:
- act as a trusted intermediary to charge user accounts on one hand, and deposit service payments to users that volunteer to provide their smartphones for CrowdSharing service, on another..
Steps
Prior to sending the first message, Bob’s smartphone, or rather the CrowdSharing agent that runs on it, would ask Alice’s counterpart whether it is OK to send. Parameters are provided, including the sha512 key-digest of the message, and the message’s size.
At this point Alice generally has 3 choices depicted above atop of the light-green background. She can flat-out say No, with possible reasons including administrative policy (“don’t trust Bob”), duplicated message (“already has or already has seen this sha512”), and others.
Alice can also simply say Yes, and then simply expect the transfer.
Or, she can try to charge Bob for the transaction, based on the criteria that takes into account:
- the current CrowdSharing market rate at a given GPS location (here again centralized Application Provider could be instrumental)
- remaining capacity and battery life (the latter – unless the phone is plugged-in)
- Alice’s data plan and its per month set limits with wireless service provider, and more.
Bob, or rather the CrowdSharing agent on his smartphone will then review the Alice’s bid and make the corresponding decision, either automatically or after interacting with Bob himself.
Payments
Payments must be postponed until the time when Alice (in the scenario above) actually pushes the message onto a wired network.
Payments must be likely carried out in points (and I suggest that each registered user deposits, say $20 for 2,000 CrowdSharing points) rather than dollars, to be computed and balanced later based on the automated review of the transaction logs by the Application Provider. Accumulated points of course must convert back into dollars on user’s request.
The challenges are impressive
The challenges, again, are impressive and numerous; there’s nothing though that I think technically is above and beyond today’s (as they say) art.
To name a few.. Downloading (getting) fobjects represent a different scenario due to the inherent asymmetry of the (Wi-Fi user, wired network) situation. BitTorrent (the first transport that comes to mind for possible reuse and adaptation) will dynamically throttle based on the amount of storage and bandwidth that each “peer” provides but is of course unaware of the consuming power and bandwidth of the mobile devices on-battery.
Extensive control path logic will have to be likely done totally from scratch – the logic that must take into account user-configurable administrative policies (e.g., do not CrowdShare if the device is currently running on-battery), the limits set by the wireless data plans 7, the ratings (see above), and more.
Aspects of the business model are in this case even more curious than technical questions.
- Wireless ad hoc network ↩
- Stochastic geometry models of wireless networks ↩
- Wireless mesh network ↩
- fobjects are files and/or objects that get created only once, retrieved multiple times, and never updated. Not to be confused with fobject as a combo of “fun and object” (urban dictionary) ↩ ↩
- Alice and Bob ↩
- Eventual consistency ↩
- In one “overage” scenario, Alice could “charge” Bob two times her own overage charges if the latter is getting reached or approximated (diagram above) ↩

{kind=link}