Foreword
As far as distributed system and storage software, finding out how it'll perform at scale - is hard.
Expensive and time-consuming as well, often impossible. When there are the first bits to run, then there’s maybe one, two hypervisors at best (more likely one though). That’s a start.
Early stages have their own exhilarating freshness. Survival is what matters then, what matters always. Questions in re hypothetical performance at 10x scales sound far-fetched, almost superficial. Answers are readily produced – in flashy powerpoints. The risk however remains, carved deep into the growing codebase, deeper inside the birthmarks of the original conception. Risk that the stuff we’ll spend next two, three years to stabilize will not perform.
The Goal
The goal is modeling the performance of a distributed system of any size (emphasis on modeling, performance and any size). Which means – uncovering the behavioral patterns (periodic spike-downs and, generally, any types of pseudo-regular irregularities), charting throughputs and latencies and their respective distributions concealed behind performance averages. And tails of those distributions, those that are in the single-digit percentile ranges.
Average throughput, average IOPS, average utilization, average-anything is not enough – we need to see what is really going on. For any scale, any configuration, any ratios of: clients and clustered nodes, network bandwidth and disk throughput, chunk/block sizes, you name it.
Enter SURGE, discrete event simulation framework written in Go and posted on GitHub. SURGE translates (admittedly, with a certain effort) as Simulator for Unsolicited and Reservation Group based and Edge-driven distributed systems. Take it or leave it (I just like the name).
Go aka golang, on the other hand, is a programming language1 2.
Go
Go is an open source programming language introduced in 2007 by Rob Pike et al. (Google). It is a compiled, statically typed language in the tradition of C with garbage collection, runtime reflection and CSP-style concurrent programming.
CSP stands for Communicating Sequential Processes, a formal language, or more exactly, a notation that allows to formally specify interactions between concurrent processes. CSP has a history of impacting designs of programming languages.
Runtime reflection is the capability to examine and modify the program’s own structure and behavior at runtime.
Go’s reflection appears to be very handy when it comes to supporting IO pipeline abstractions, for example. But more about that later. As far as concurrency, Rob Pike’s presentation is brief and to the point imho. To demonstrate the powers (and get the taste), let’s look at a couple lines of code:
In this case, notation 'go function-name' causes the named function to run in a separate goroutine – a lightweight thread and, simultaneously, a built-in language primitive.
Go runtime scheduler multiplexes potentially hundreds of thousands of goroutines onto underlying OS threads.
The example above creates a bidirectional channel called messages (think of it as a typed Unix pipe) and spawns two concurrent goroutines: send() and recv(). The latter run, possibly on different processor cores, and use the channel messages to communicate. The sender sends random ASCII codes on the channel, the receiver prints them upon reception. When 10 seconds are up, the main goroutine (the one that runs main()) closes the channel and exits, thus closing the child goroutines as well.
Although minimal and simplified, this example tries to indicate that one can maybe use Go to build an event-distributing, event-driven system with an arbitrary number of any-to-any interconnected and concurrently communicating players (aka actors). The system where each autonomous player would be running its own compartmentalized piece of event handling logic.
Hold on to this visual. In the next section: the meaning of Time.
Time
In SURGE every node of a modeled cluster runs in a separate goroutine. When things run in parallel there is generally a need to go extra length to synchronize and sequence them. In physical world the sequencing, at least in part, is done for us by the laws of physics. Node A sending message to remote node B can rest assured that it will not see the response from node B prior to this sent message being actually delivered, received, processed, response created, and in turn delivered to A.
The corresponding interval of time depends on the network bandwidth, rate of the A ⇔ B flow at the time, size of the aforementioned message, and a few other utterly material factors.
That’s in the physical world. Simulated clusters and distributed models cannot rely on natural sequencing of events. With no sequencing there is no progression of time. With no progression there is no Time at all – unless…
Unless we model it. For starters let’s recall an age-old wisdom: time is not continuous (as well as, reportedly, space). Time rather is a sequence of discrete NOWs: one indivisible tick (of time) at a time. Per quantum physics the smallest time unit could be the Planck time ≈5.39*10-44s although nobody knows for sure. In modeling, however, one can reasonably ascertain that there is a total uneventful void, literally nothing between NOW and NOW + 1.
In SURGE, the smallest indivisible tick of time is 1 nanosecond, a configurable default.
In a running operating physical cluster each NOW instant is filled with events: messages ready to be sent, messages ready to be received, events being handled right NOW. There are also en route messages and events sitting in disk and network queues and waiting for their respective future NOWs.
Let’s for instance imagine that node A is precisely NOW ready to transmit a 8KB packet to node B:

Given full 10Gbps of unimpeded bandwidth between A and B and the trip time, say, 1µs, we can then with a high level of accuracy predict that B will receive this packet (819ns + 1µs) later, that is at NOW+1.819µs as per the following:
In this snippet of modifiable-and-runnable code, the local variable sizebits holds the number of bits to send or receive while bwbitss is a link bandwidth, in bits per second.
Time as Categorical Imperative
Here’s a statement of correctness that, on the face of it, may sound trivial. At any point in time all past events executed in a given model are either already fully handled and done or are being processed right now.
A past event is of course an event scheduled to trigger (to happen) in the past: at (NOW-1) or earlier. This statement above in a round-about way defines the ticking living time:
At any instant of time all past events did already trigger.
And the collateral:
Simulated distributed system transitions from (NOW-1) to NOW if and only when absolutely all past events in the system did happen.
Notice that so far this is all about the past – the modeled before. The after is easier to grasp:
For each instant of time all future events in the model are not yet handled - they are effectively invisible as far as designated future handlers.
In other words, everything that happens in a modeled world is a result of prior events, and the result of everything-that-happens is: new events. Event timings define the progression of Time itself. The Time in turn is a categorical imperative – a binding constraint (as per the true statements above) on all events in the model at all times, and therefore on all event-producing, event-handling active players – the players that execute their own code autonomously and in parallel.
Timed Event
To recap. Distributed cluster is a bunch of interconnected nodes (it always is). Each node is an active Go player in the sense that it runs its own typed logic in its own personal goroutine. Nodes continuously generate events, assign them their respective computed times-to-trigger and fan them out onto respective Go channels. Nodes also continuously handle events when the time is right.
By way of a sneak peek preview of timed events and event-driven times, here’s a life of a chunk (a block of object’s data or metadata) in one of the SURGE’s models:
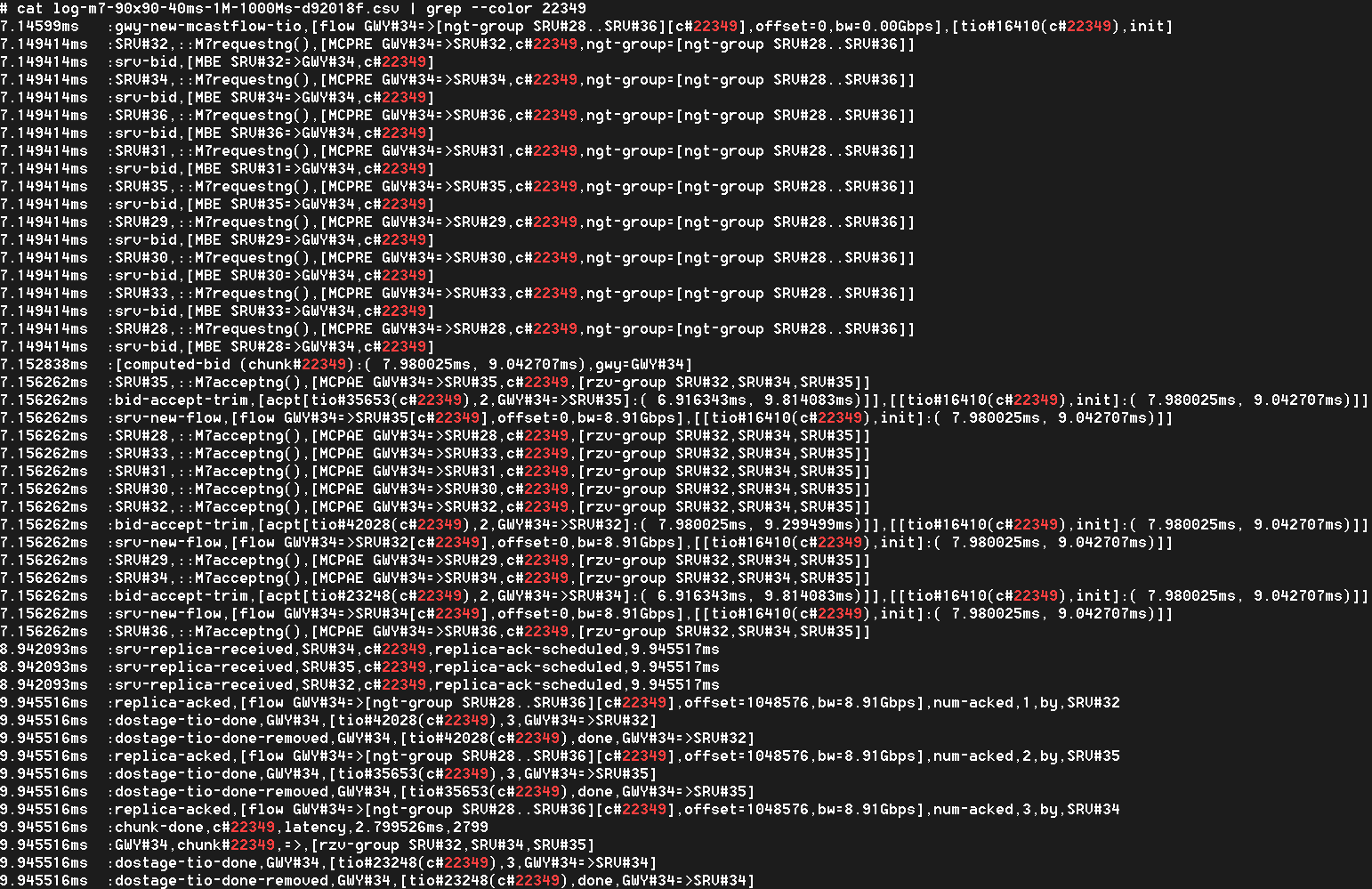
The time above runs on the left, event names are abbreviated and capitalized (e.g. MCPRE). With hundreds and thousands of very chatty nodes in the model, logs like this one become really crowded really fast.
In SURGE framework each and every event is timed, and each timed event implements the following abstract interface:
type EventInterface interface {
GetSource() RunnerInterface
GetCreationTime() time.Time
GetTriggerTime() time.Time
GetTarget() RunnerInterface
GetTio() *Tio
GetGroup() GroupInterface
GetSize() int
IsMcast() bool
GetTioStage() string
String() string
}
This reads as follows. There is always an event source, event creation time and event trigger time. Some events have a single remote target, others are targeting a group (of targets). Event’s source and event’s target(s) are in turn clustered nodes themselves that implement (RunnerInterface).
All events are delivered to their respective targets at prescribed time, as per the GetTriggerTime() event’s accessor. The Time-defining imperative (above) is enforced with each and every tick of time.
In the next installment of SURGE series: ping-pong model, rate bucket abstraction, IO pipeline and more.












{kind=link}