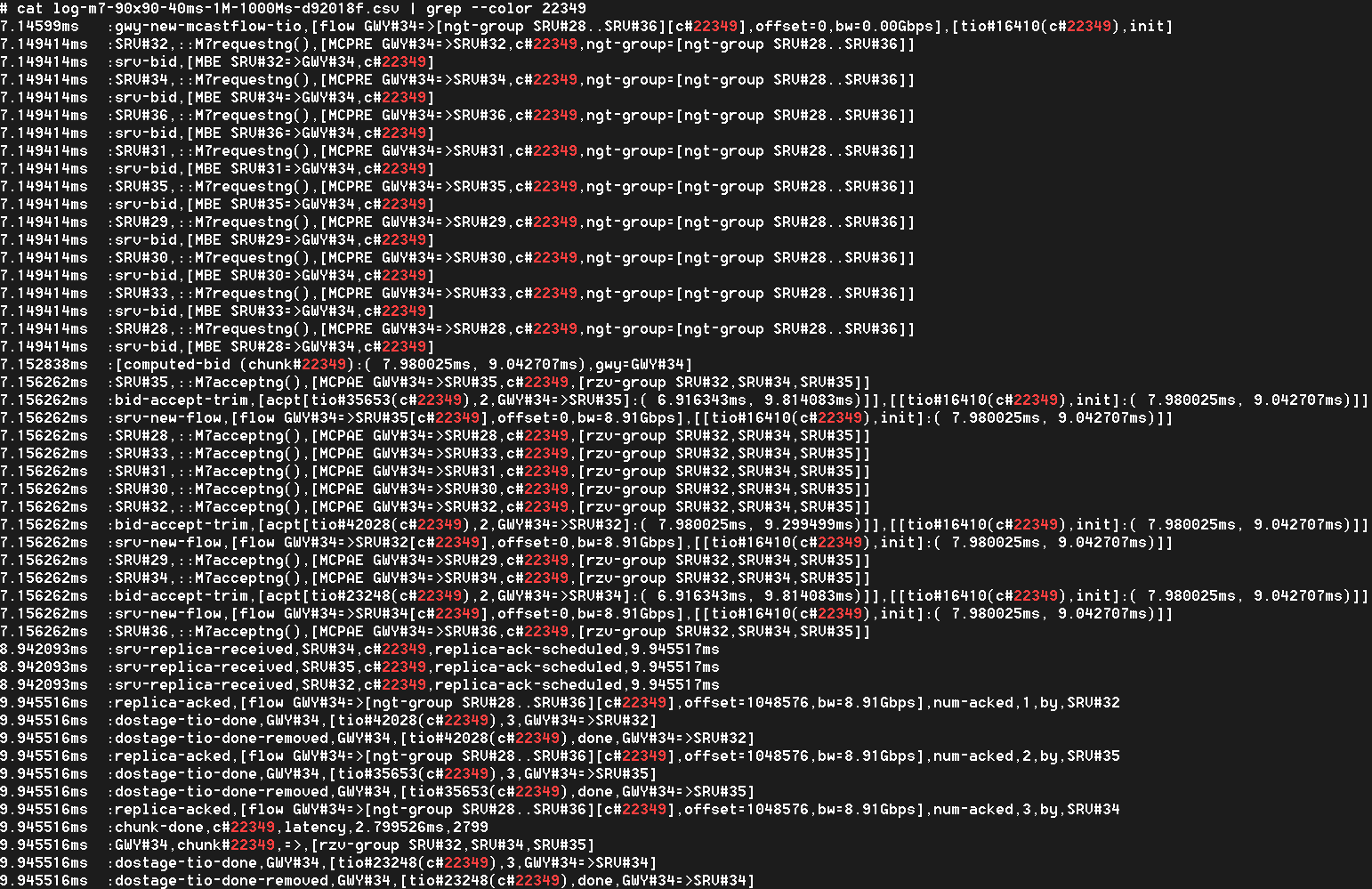
In a fully distributed storage cluster (FDSC), one possible design choice for a new storage protocol is resource reservation (RR). There are certain distinct challenges though, when working out an optimal RR schema. On the storage initiator side, one critical question that arises is whether to accept an RR response a.k.a. a bid from a given target for a given I/O request. Or, alternatively, try to renegotiate, in hopes of getting a better reservation.
The absolutely best reservation is, of course, the one that allows I/O in question to start immediately and execute at full throttle.
Hence, choosy initiator in the title, the storage initiator that grapples with the dilemma: go ahead and accept possibly suboptimal arrangement, or renegotiate. The latter inevitably comes with the risk to receive future reservations that are even more delayed.
To bet or not to bet, that is the question. To find out, I’ve used SURGE: a discrete open source event simulation framework written in Go (https://golang.org/doc/). The source includes a bunch of concrete protocol models (that run) and the usual README to get started.
OK, let’s do some definitions.
FDSC and RR
The three key aspects of a FDSC are self-containment, full connectivity, and hashed distribution:
- Self-containment: each clustered node is a sole owner of its local resources: disks, CPU, memory, and link bandwidth;
- Any-to-any: all nodes are interconnected through non-blocking, no-drop network core;
- Hashed memoryless distribution: a given I/O request is mapped or hashed to a number of storage target. For writes, the number of targets must be equal or greater than the required redundancy. This I/O mapping/hashing operation does not depend on the history and on any of the previously executed I/O requests (hence, memoryless).
Note separately that the letter ‘S’ in FDSC also reads as “symmetric”. In symmetric clusters, each node performs a dual role of storage initiator and storage target simultaneously.
For now let’s just say that large fully distributed clusters counting hundreds or thousands initiators and targets require a different intra-cluster transport. That’s #1, the point that maybe does not sound very controversial. To add controversy (just for the heck of it), here’s the point #2: for large and super-large FDSC it makes a lot of sense to use RR based transport protocols. One of the key proof points boils down to convergence.
Convergence time is the time it takes for existing link-sharing (path-sharing) flows to converge on their respective optimal rates when a new flow is being added or an existing flow removed. All things being equal, each of the N flows eventually must take 1/Nth of the total bandwidth.
Figure 12 in the research paper at http://goo.gl/JUlijH shows DCTCP convergence times.
Red flow (below) is added after the blue flow has reached its steady and close-to-optimal state. The research estimates DCTCP convergence times on a 10GE network ranging anywhere from 229*d to 770*d, where d is the propagation delay. This is a considerable time corresponding to several fully transferred 128K payloads even for a very favorable (as far as speedy convergence) value of d in the order of few microseconds.
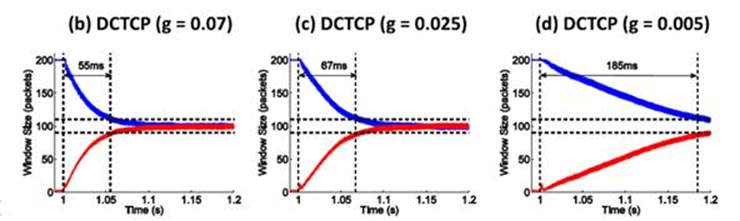
In presence of multiple flows the picture gets substantially more messy but the bigger point is: irrespective of the particular link-sharing transport, during the time N flows are converging from (N-1) or (N+1), they all execute at sub-optimal rates resulting in overall sub-optimal network utilization. Hence, an appeal of the RR approach: eliminate resource sharing. Utilization time slots are simply negotiated. There will be no unexpected start-IO, complete-IO, and add-flow, delete-flow events in the middle.
If there exists anything similar in real life, that could be a timeshare ownership. On the networking side examples include RSVP in its unicast and multicast realizations (RFC2205).
In all cases (including timeshare) and independently of the concrete resource reservation protocol, each successful RR negotiation comes with a time window in combination with a full set of requested targets resources – for exclusive usage (during a given time window) by a given pending request (emphasis on exclusive). For each I/O request, there is a natural progression:
I/O request =>
potential targets =>
RR negotiation(s) =>
data flows to/from ...
This results in network flows executing as prescribed by non-overlapping time windows granted in turn by the respective selected targets.
To bet or not to bet
The figure below shows one possible “resource reservation, renegotiated” (RRR) scenario:
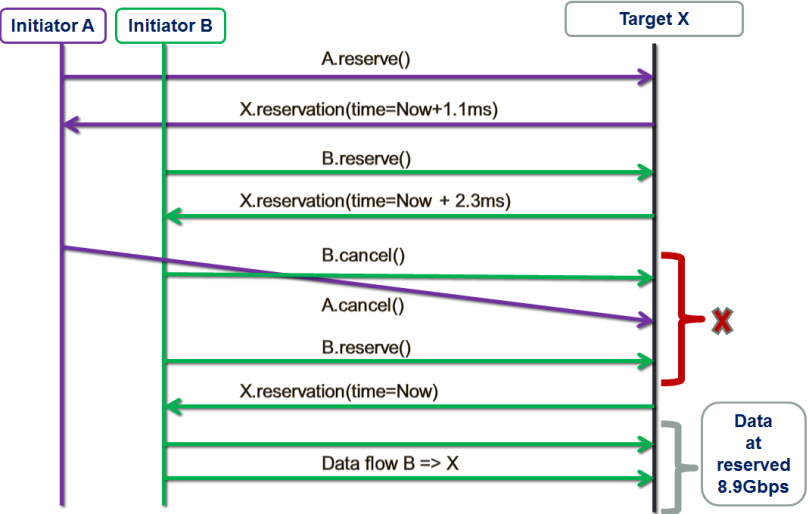
There are two storage initiators: purple A and green B. The initiators are trying to establish data flows with the same target X at approximately the same time.
First, initiator A tentatively reserves target X for a window starting 1.1ms later (from now), which roughly corresponds to the time target X needs to complete a (presumably) already queued 1MB transaction (not shown here).
Next, initiator B tentatively reserves X for the adjacent X’s time window at 2.3ms from now. Red X on the picture indicates the decision point.
In this example, instead of accepting whatever is presented to it at the moment, B decides that 2.3ms is too much of a delay and cancels. Simultaneously, A cancels as well, possibly because it has obtained more attractive bids from other storage targets that are not shown here. This further results in B getting the optimal reservation and utilizing it right away.
Simulation
The idea that at least sometimes it does make sense to take a risk and renegotiate requires proof. Fortunately, with SURGE we can run massive simulations to find out.
Replicast is a one FDSC-friendly RR-based protocol that was previously described – see for instance SNIA presentation Beyond Consistent Hashing and TCP.
Replicast-H (where H stands for hybrid) entails multicast control plane and unicast data. Recall that RR negotiation is a part of the reservations-based protocol control plane. When running a hybrid version of the Replicast, we negotiate up to (typically) 3 successive time windows to perform a write. We then often see the following picture:
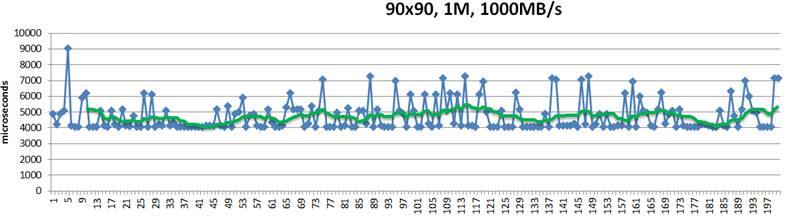
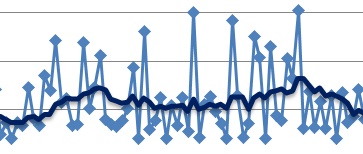
Figure 3. Reservations without renegotiation
This above is a 200-point random sample that details latencies of 1MB size chunks written into their hashed target destinations. Green trendline in the middle shows 10-point moving average. This is a “plain” Replicast-H benchmark where each target’s bid is taken at a face value and never renegotiated.
The cluster in this case combines 90 targets and 90 storage initiators with targets operating at 1000MB/s disk throughput. Finally, there is a non-blocking no-drop 10Gbps that connects each target with each initiator.
In the simulation above 10% of the bandwidth is statically allocated for control traffic. With 1% accounting for network headers and miscellaneous overhead, that leaves 8.9Gbps for (pure) data.
In the idealistic conditions when a given initiator does not have any competition from others, the times to execute a 1MB write to a single target would be, precisely:
- Network: 941.482µs
- Disk: 1ms
Given 3 copies, the request could (ideally) be fully executed in slightly more than 4 milliseconds, including control handshakes and acknowledgements.
There is, however, inevitably a competition resulting in reservation conflicts and delays, and further manifesting itself in occasional end-to-end spikes up to 7ms latency and beyond – see the picture above.
In depth analysis of traces (that I will skip here) indicates that, indeed, one possible reason for the spikes is that initiators accept reservations too early. For instance, the initiator that executed the #5 in the sample (Fig. 3) could likely do better.
Unicast delivery with renegotiation
This “with renegotiation” flavor of the protocol adds a new configuration variable that currently defaults to 3 times RTT on the control plane:
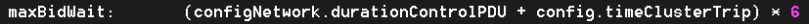
Note: to go directly to the github source, click this and other similar code fragments. At runtime, this model will double the wait time and renegotiate reservations if and when the actual waiting time (denoted as ‘idletime’ below) exceeds the current value:
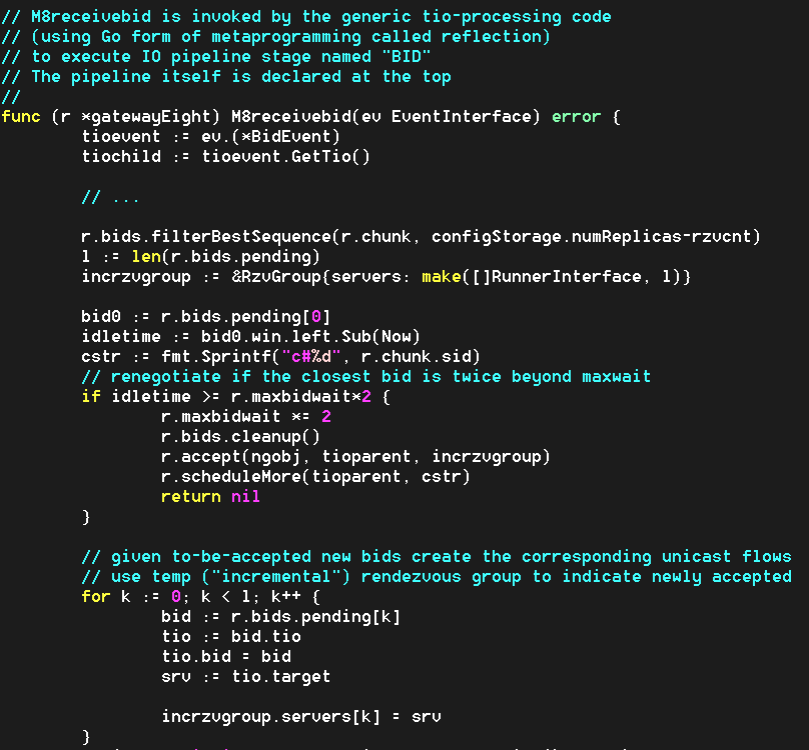
In addition, since 3 times RTT is just a crude initial guess, each modeled gateway (a.k.a. storage initiator) recomputes its value (‘r.maxbidwait’ in the code) for the next write request, averaging the previous value and the current one:

What happens after the first few transactions is that each initiator independently computes an objective average delay and from there on renegotiates only when the newly collected reservations collectively result in substantially bigger delay (in other words, the initiator renegotiates only when it “thinks” it could get a better deal).
Here’s the SURGE-simulated result for apples-to-apples identical configuration that runs 90 storage initiators and 90 storage targets, etc.:
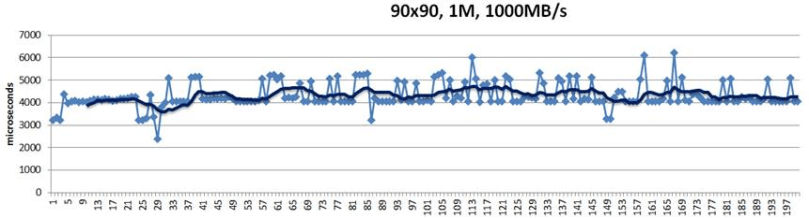
Notice that there are no 7ms spikes anymore. They are simply gone.
Conclusions, briefly
For differently sized chunks and disk/backend throughputs, the average improvement ranges from 8% to 20%:
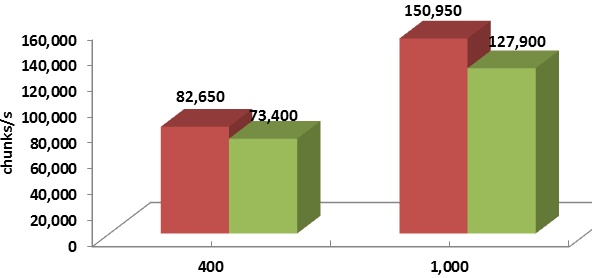
Legend-wise, red columns depict the “with renegotiation” version.
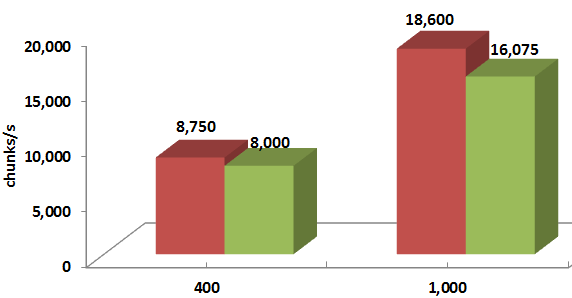
Thus, taking a risk does seem to pay off: RR based protocol where storage initiators are “choosy” and at least sometimes renegotiate their reservations outperforms its prior version.