Suppose, you’ve come across a set of 10 billion unique objects that are stored far, far away. You can now read them all, although that may at times be painfully slow, if not downright sluggish. And it may be costly as well – a couple cents per gigabyte quickly runs up to real numbers.
You also have a Data Center, or, to be precise, a colocation facility – a COLO. With just a handful of servers, and a promise to get more if things go well. Say, a total of N > 1 servers at your full disposal. The combined capacity of those N servers will not exceed one million objects no matter what – 0.01% of grand total.
Last but not the least, you’ve got yourself a machine-learning project. The project requires each compute job to read anywhere from 100K to 1M random objects out of the 10 billion stored far, far away. The greediest batch job may consume, and then try to digest, close to a million but no more.
Therein lies the question: how to utilize your N-server resource for optimal (i.e., minimal) read latency and optimal (i.e., minimal) outbound transfer cost?
Researching and Developing. Coding.
The reality of R&D is that it’s not like in the movies. It is mundane, repetitive. You tweak and run and un-tweak and rerun. This process can go on and on, for hours and days in a row. Most of the time, though, the job that undergoes the “tweaking” would want to access the same objects.
Which is good. Great, actually, because of the resulting, uneven and unbalanced, distribution of the hot/cold temperatures across the 10-billion dataset. This is good news.
In real life, there are multiple non-deterministic factors that independently collaborate. Running 27 tunable flavors of the same job can quickly help to narrow down the most reusable object set. Impromptu coffee break (factor) presenting a unique opportunity to run all 27 when the rest of the team is out socializing. And so on.
More often, though, it’d be a work-related routine: a leak or a crash, a regression. The one that, down the road, becomes reproducible and gets narrowed to a specific set of objects that causes it to reproduce. The latter then is bound to become very hot very soon.
In pursuit of balance
For whatever reason, the title phrase strongly associates itself with the California pinot noir and chardonnay. There’s the other type of balance though – the one that relates to software engineering. In particular, relates to read caching.
DHT is, maybe, the first thing that comes to mind. The DHT that would be mapping object IDs (OID) to their server locations, helping us to realize the most straightforward implementation of a distributed read cache.
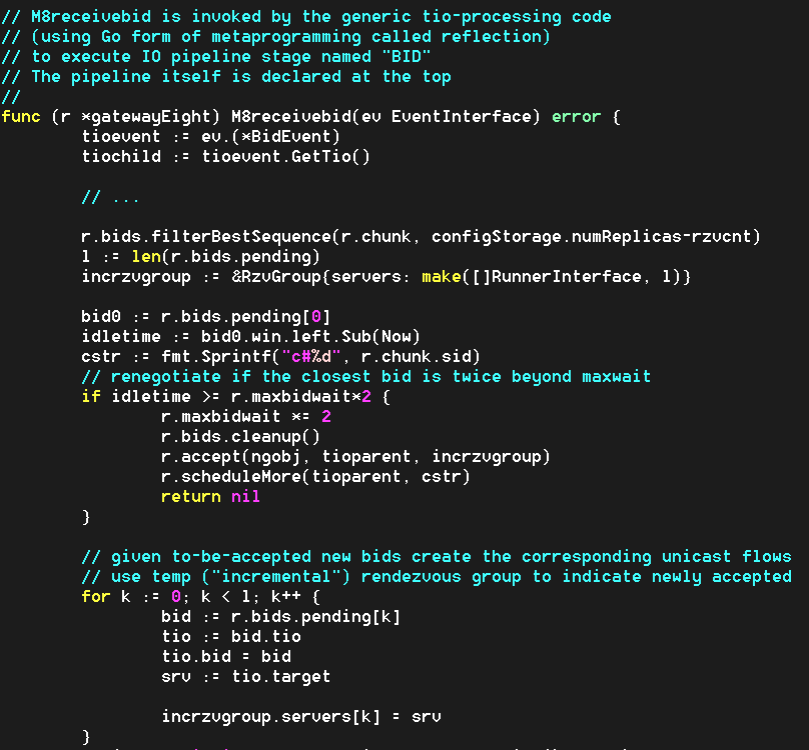
Conceptually, when an object with OID = A shows up in its local server space computing job would execute DHT.insert(A). And then, DHT.delete(A) when a configured LRU/LFU/ARC policy triggers the A’s eviction. The operations would have to be transactional, so that DHT.get() always gets consistent and timely results.
There is a price though. For starters, the task of managing local caches does not appear to be the first concern when all you need is to make your zillion-layer neural network converge (and it wouldn’t).
Thus, the DHT (or whatever is the implementation of the cluster-wide key/value table) would have to be properly offloaded to a separate local daemon and, project-wise, relegated to the remainder of working hours.
Next, there is a flooding concern. A modest 1K objects-per-second processing rate by 10 concurrent jobs translates as 20K/s inserts and deletes on the DHT. That’s not a lot in terms of bandwidth but that is something in terms of TCP overhead and network efficiency. The control-messaging overhead tends to grow as O(number-of-jobs * number-of-servers) to ultimately affect the latency/throughput of critical flows.
In addition, local DHT daemon will have to discover other DHT daemons and engage them in a meaningful, albeit measured, conversation including (for starters) keep-alive and configuration-change handshakes. So that everyone keeps itself in-sync with everyone else, as far as this (meticulous) object tracking and stuff.
Further, there’s the usual range of distributed scenarios: servers joining and leaving (or crashing, or power-cycling, or upgrading), spurious messaging timeouts, intermittent node failures, inconsistent updates. Think distributed consensus. Think false-positives. Think slipping deadlines and headaches.
And then there is persistence across reboots – but I’ll stop. No need to continue in order to see a simple truth: the read-caching feature can easily blow itself out of all proportions. Where’s the balance here? Where is the glorified equilibrium that hovers in the asymptotic vicinity of optimal impact/effort and cost/benefit ratios? And why, after all, when California pinot noir and chardonnay can be perfectly balanced – why can’t the same be done with software engineering of the most innovative machine-learning project that simply wants to access its fair share of objects stored far, far away?
The pause
The idea is as old as time: trade distributed state for distributed communications, or a good heuristic, or both. Better, both.
Hence, it’d be very appropriate at this point to take a pause and observe. Look for patterns, for things that change in predictable ways, or maybe do not change at all…
When object sets are static
It appears that many times the compute jobs would know the contents of their respective object sets before their respective runtimes. Moreover, those objsets can be totally preordered: an object B would follow an object A iff the B is processed after the A, or in parallel.
The phenomenon can be attributed to multiple runs and reruns (previous section) when all we do is update the model and see if that works. Or, it can be ascribed to searchable metadata that happens to be stored separately for better/faster observability and analytics. Whatever the reason, the per-job list of object IDs can be compiled and broadcast to the clustered servers, accompanied with the message to please hold-on to those objects if they are local.
More precisely, the steps are:
- A job that is about to start executing broadcasts the list of its OIDs as well as per-OID (min, max, location) records of when and where it’ll need the objects preloaded;
- Each of the (N-1) control plane daemons responds back with a message consisting of a bunch of (OID, t1, t2) tuples, where OID is an object ID and:
- t1 = 0, t2 > 0: the object is local at the responding server, and the server commits to keep it until at least time = t2
- t1 > 0, t2 > t1: the object is not currently present at the responding server; the server, however, makes a tentative suggestion (a bid) to load it by the time t1 and keep it until the time t2
- Finally, the job collects all the responses and in turn responds back to all the bids canceling some of them and confirming the others.
So that’s that – the fairly straightforward 3-step procedure that converges in seconds or less. There are, of course, numerous and fine details. Like, for instance, how do we come up with the t1 and t2 estimates to balance the load of already started or starting jobs while not degrading the performance of those that may come up in the future. Or the question of how to optimally calibrate the bidding process at runtime. And so on.
Those are the types of details that are beyond the point of this specific text. The point is, utilize both the prior knowledge and the combined N-server resource. Utilize both to the maximum.
When object sets are dynamic
But what if the object sets are not static, as in: Could we still optimize when the next object is not known until the very last moment it needs to be processed? Clearly, the problem immediately gets infinitely trickier. But not all hope is lost if we take another pause…
Could we still optimize when the next object is not known until the very last moment it needs to be processed? Clearly, the problem immediately gets infinitely trickier. But not all hope is lost if we take another pause…
– to experiment a bit and observe the picture:

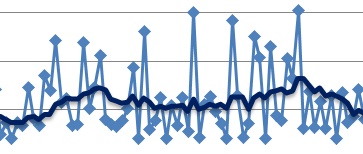
Fig 1. Percentage of virtually snapshotted objects as a function of elapsed time.
No, this is not an eternal inflation of the multiverse with bubble nucleation via quantum tunneling. This is a tail distribution aka CCDF – the percentage of objects that remain local after a given interval of time – a cluster-wide survival function. To obtain that curve, a simple script would visit each server node and append its local object IDs to a timestamped log, in effect creating a virtual snapshot of the clustered objects at a given time.
Later, the same script uses the same log to periodically check on the (virtually snapshotted) objects. In the Fig. 1, the bump towards the end indicates reuploading of already evicted objects – the fact that strongly indicates suboptimal behavior of the system. Subsequently, after factoring-in environmental differences and gaussian noise (both causing the shape of CCDF to falter and flap across job runs and coffee breaks), we obtain this:

Fig 2. Survival function with noise
One observation that stands strong throughout the experiments is that an object almost never gets evicted during the first time talive interval of its existence inside the compute cluster. As time goes by, the chances to locate most of the original virtual snapshot in the cluster slowly but surely approach zero depicted as a fuzzy reddish area at the bottom of the Fig. 2.
The fork
Clearly, for any insight on the dynamic object locations, we need to have some form of virtual snapshotting. Introduce it as a cluster-wide periodic function, run it on every clustered node, broadcast the resulting compressed logs, etc.
But how often do we run it? Given an observed average lifecycle of a virtual snapshot T (Fig. 2), we could run it quite frequently – say, every max(T/10,000, 1min) time, to continuously maintain an almost precise picture of object locations (all 10 billion of those).
Alternatively, we could run it infrequently – say, every min(T/2, talive) – and derive the corresponding P(is-local) probabilities out of the approximated survival function.
Hence, the dilemma. The fork in the road.
Bernoulli
Since the “frequent” option is a no-brainer (and a costly one), let’s consider the “infrequent” option first, with the intention to make it slightly more frequent in the future, thus approximating the ultimate optimally-balanced compromise. Given an object’s OID and bunch of outdated virtual snapshots, we should be able to track the object to the last known time it was uploaded from far, far away. Let’s call this time toid:

Fig 3. Bernoulli trial
Next, notice that for any two objects A and B, and a sufficiently small interval dt the following would hold: That is, because the objects that have similar local lifetimes within the compute cluster must also have similar chances of survival.
That is, because the objects that have similar local lifetimes within the compute cluster must also have similar chances of survival.
Further, select a sufficiently small dt (e.g., dt = (T – talive – tdead)/100) and, when a job starts executing, gradually gather an evidence denoted in the Fig. 3 as yes and no for: “object is local” and “not local”, respectively. Each small interval then automatically becomes an independent Bernoulli trial with its associated (and yet unknown) probability p(dt) and the Binomial PMF: The question is how we can estimate the p for each or some of the 100 (or, configured number of) small intervals. One way to do it is via Bayesian posterior update that takes in two things:
The question is how we can estimate the p for each or some of the 100 (or, configured number of) small intervals. One way to do it is via Bayesian posterior update that takes in two things:
- the prior probability p, and
- the Bernoulli trial evidence expressed as two integers: n (number of objects) and k (number of local objects),
and transforms all of the above into the posterior probability distribution function: Here’s how this formula is working out. Recall that n and k are two counters that are being measured on a per dt basis. On the right side of the equation, we have the Bayes’ theorem that divides the prior probability (of k successes in the n Bernoulli trials) by the total probability (of k successes in the n Bernoulli trials). The prior in this case corresponds to our belief that the real probability equals p.
Here’s how this formula is working out. Recall that n and k are two counters that are being measured on a per dt basis. On the right side of the equation, we have the Bayes’ theorem that divides the prior probability (of k successes in the n Bernoulli trials) by the total probability (of k successes in the n Bernoulli trials). The prior in this case corresponds to our belief that the real probability equals p.
On the left side, therefore, is a posterior probability distribution function parametrized by p – a formula of the most basic type y = f(x) which can be further used to estimate the expected value and its variance, integrate across intervals (to approximate parts of the CDF), and so on.
Wrapping up
The formula above happens to be the standard Beta distribution. Which means that from gathering per-interval statistics to estimating per-interval probabilities, there is a single step that sounds as follows: go ahead and look up the corresponding Wikipedia page. Arguably, that step can be performed just once, maybe two or (max) three times.
That helps. What helps even more is the general downtrend of the survival functions, from which one can deduce that “giving up” on finding the objects locally for a certain specific interval (ti, ti + dt) can be followed by abandoning ongoing efforts (if any) to compute the probabilities to the right of this ti.
Further, the notion of “giving up” vs “not giving up” will have to be defined as a threshold probability that is itself a function of the cumulative overhead of finding the objects locally, normalized by the number of successful finds.
However. It is incumbent upon us to wrap it up. Other fascinating details pertaining to the business of handling treasure troves of billions, trillions, and Graham numbers of objects will have to wait until they can be properly disclosed.
All in due time.


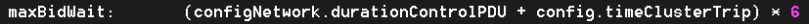





{kind=link}