
The seismic shift
Fact is, NAND media is inherently not capable of executing in-place updates. Instead, the NAND device (conventionally, SSD) emulates updates via write + remap or copy + write + remap operations, and similar. The presence of such emulation (performed by SSD’s flash translation layer, or FTL) remains somewhat concealed from an external observer.
Other hardware and software modules, components and layers of storage stacks (with a notable exception of SMR) are generally not restricted by similar intervention of one’s inherent nature. They could do in-place updates if they’d wanted to.
Nonetheless, if there’s any universal trend in storage of the last decade and a half – that’d be avoiding in-place updates altogether. Circumventing them in the majority of recent solutions. Treating them as a necessary evil at best.
The language got created to fill in the gaps between the must-update, on the one hand, and can’t or won’t, on another. The language, rich in connotations, particularly includes:
- multi-versioning (both with and without its optimistic CC part),
- copy-on-write (CoW)
- redirect-on-write (also CoW)
- B-tree shadowing
- differential (delta) updates
- log-structured (filesystems, stores on SSD, etc.)
- blockchain (databases), and more.
There are supercool CS structures that support all of the above with very fine algorithms, including log-structured merge-tree (LSM tree), BW-tree, and SILT – to name just a few on the Key-Value storage side.
And on the feature/capability front, all of the above brought about instantaneous snapshots, distributed clones, shadow migration, writeback logging, writeback caching, deferred compression, transparent rebalancing, and more. All the good stuff that has become only possible (or, possible at scale) with advent of multi-versioned, log-structured, copy-on-write etc. storage. The software that does not update in-place.
There’s a fundamental reason for this: in-place updating is information-lossy and therefore irreversible. For fear of sounding too vague or too broad, I’ll say there’s a link between increased entropy of the storage system and its (diminishing) capability to do unlimited snapshots. And the bottom line is, there’s a fault line, largely unnoticed and unacknowledged, with storages that do in-place updating and those that don’t – on each side of the widening divide. With ardent believers on both sides.
And the bottom line is, there’s a fault line, largely unnoticed and unacknowledged, with storages that do in-place updating and those that don’t – on each side of the widening divide. With ardent believers on both sides.
The question
What’s better for (and with) SSDs, performance and durability-wise?
Take ZFS for instance. ZFS always writes to a new location. SSD controller always writes to a new location. Wouldn’t these two play well together, be in some deeper sense more agreeable? Shouldn’t ZFS, Btrfs, WAFL, and (log-structured) F2FS be more optimal, maybe in a long run, than in-place updaters ext4 and xfs? Couldn’t we observe some definitive but positive effects by stacking up only the purest, the most dedicated non-in-place updaters on top of SSDs, and measuring the results?
This is BIG. Those questions are complex, existential, and outside the scope (i.e., command a lot more examination). For starters though, one specific and closely related topic would be: recycling of flash memory pages. Recycling of flash memory pages – let’s take a look:
Recycling of flash memory pages – let’s take a look:
Read/write Page, erase Block
NAND flash was first introduced into the 1980s’ consumer market. The very first 20MB SSD was separately sold for $1000 (i.e., $50K/GB) and shipped in the 1990s.
The thing to remember about any solid-state device is that, as far as the device itself is concerned, reads and writes are done in multiples of pages, erases – in units called erase blocks (or simply, blocks). A block of flash storage in turn contains fixed number of same-size pages.
Those are fundamental facts that were true back in the early days and will remain true until the very last NAND chip gets used, burned and discarded. Until and unless, though, notice (and file away) the 3rd added primitive: erase-block or, simply, erase.
The size of a NAND page and number of pages in a block fluctuate from vendor to vendor and from model to model, with a tendency to double and quadruple in correlation with (growing) usable capacity of the device in question. SSD vendors do not like to disclose page and block sizes, or any configuration details beyond the most basic ones. On the other hand, vendors are definitely and resolutely averse to disclosing the secret embedded “sauce”: the flash translation layer. FTL is the SSD controller-resident firmware that makes SSD look like a conventional magnetic drive (aka hard drive), albeit with no moving parts.
To accomplish this transformation, FTL continuously remaps flash memory pages, balances writes, keeps bad blocks separated from good ones, un-disturbs reads and corrects errors. It is the FTL that executes the erase-block primitive – when the timing is right.
One updating sequence
Garbage collection, wear leveling, dealing with write amplification and at all times protecting user data – the list of FTL functions goes on and on. For any reasonable person, this list alone would immediately raise a big flashing-red sign, with not-in-sync warning written all over it. Indeed, host-based storage software and FTL execute their respective logics not exactly in-sync. Very far from what one would call a lockstep. These two do not really know what %&^!& the other is doing at any point in time.
Take a simplified sequence that a CoW filesystem executes when first writing and then updating a filesystem-addressable piece of storage space called “logical block”: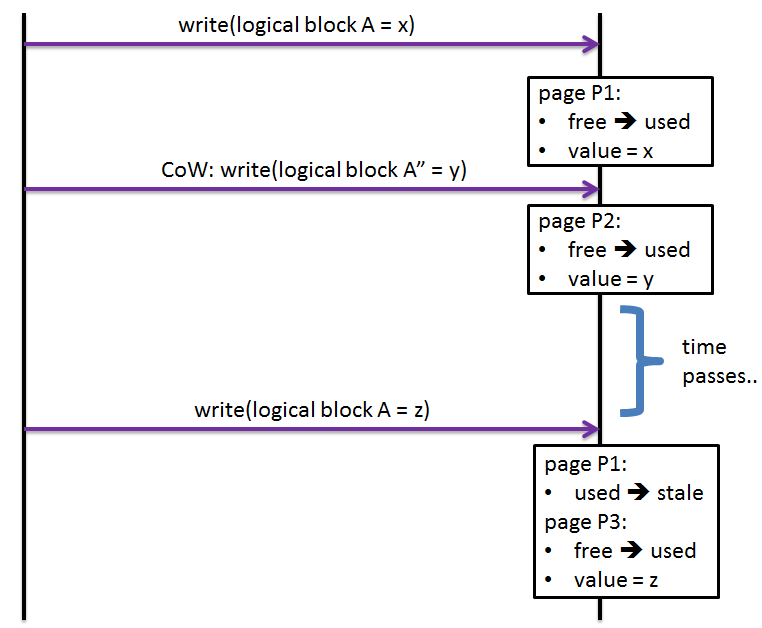 Fig. 1: One updating sequence
Fig. 1: One updating sequence
First, newly allocated logical block A gets associated with a namesake filesystem object A.
- Assuming size of the A is less or equal one page, the write operation proceeds to write A = x into a fresh SSD page P1.
Next, copy-on-write update of the same object A instantiates a new logical block A”.
- This time a new page P2 gets allocated for the object A by the SSD’s FTL, and is written with the object’s new value ‘y’ (some sticklers will stubbornly insist on calling this type of an update redirect-on-write rather than copy-on-write)
- Time passes, during which the SSD is unaware that A’s value is ‘y’ and that the page P1 may not necessarily be in use.
Finally, the original logical block A gets reused by the filesystem itself, possibly and most likely for a different filesystem object. The write then happens resulting in new value ‘z’ trying to “hit” the same page P1 that was originally mapped to A (step #1 above).
- But since SSDs do not update in-place, the P1 gets (finally) marked by the FTL as being stale, new page P3 allocated, logical block A remapped to the P3, and value ‘z’ written down.
Page state transitions: who’s in control?
The Fig. 1 sequence can be summarized as a lifecycle of an SSD page, during which it continuously bounces between the following 3 basic states: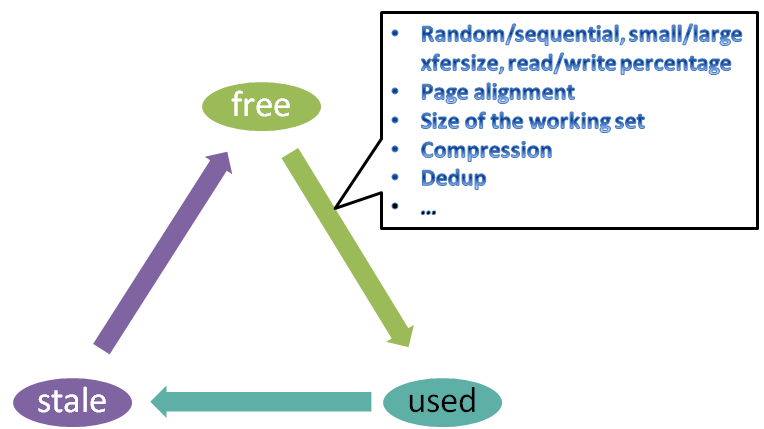 Fig. 2: State transitions (simplified)
Fig. 2: State transitions (simplified)
A page starts free and then transitions to used. How soon depends in part on the type/characteristics of the workload and size of the working set relative to the size of the device (Fig. 2). Once a page becomes used, it then stays used for a while – until it becomes not used anymore. At which point it becomes stale.
Overall, the amount of control by the storage software and firmware over page transitions is increasing clockwise on the diagram. The 3rd depicted (stale ⇒ free) transition happens to be under full FTL’s control. With one small correction – stale page can transition to free only together with all its page “neighbors” within the same block:
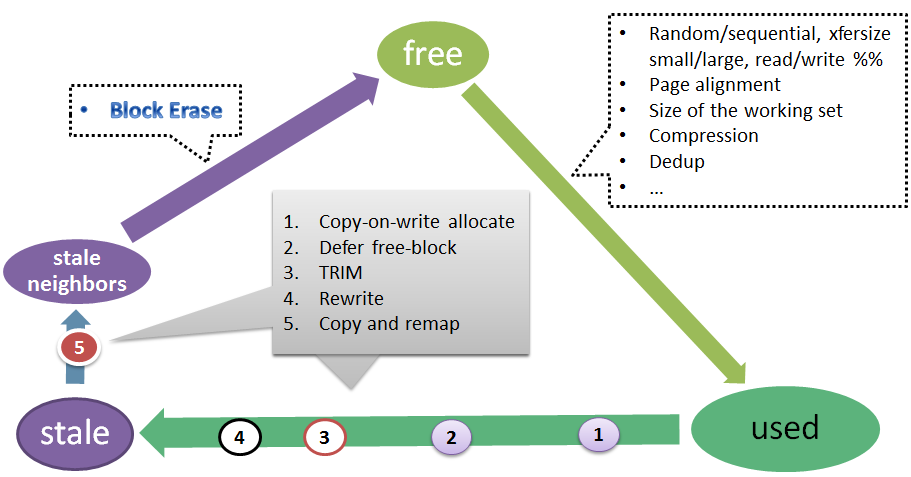 Fig. 3: Transition used ⇒ stale: delaying or speeding it up
Fig. 3: Transition used ⇒ stale: delaying or speeding it up
There’s a number of factors affecting the horizontal transition (Fig. 3): putting it off or speeding it up. One of the speeding factors is FTL’s own GC logic that may decide at one point to transfer a perfectly used page into a different block – notice the little circle marked #5 on the picture.
On the other hand, host based storage software may go a long way to postpone the aforementioned transition. ZFS, for instance, always defers #2 frees (and therefore reuse via #4 rewrite) of its logical blocks. The actual postponement is typically 6 to 10 seconds depending on workload and tunables – ZFS does it in order to allow rollback of the last few-seconds of changes, just in case.
On the third hand, the host can expedite used ⇒ stale with either in-place updates or, better, deletes followed by TRIM/UNMAP (#3 on Fig. 3).
It can also postpone the latter with copy-on-write updates in combination with any kind of TRIM deferring (scheduling, batching) logic. Or, not use (not support) the TRIMs at all. Those are some of the possibilities.
Consider one extreme (in its simplicity) scenario where the workload is steady in-place update (100% write) carrying perfectly page-aligned and page-sized payload. At any point in time the number of stale pages in this case will be close to:
number-stale-pages = write-IOPS*write-latency-in-secs – working-set-size/page-size
Steady state and 100% in-place update means the left side of this formula is a constant. To sustain this workload, all FTL would have to do is run erase-block at the write-IOPS/number-pages-in-block rate.
It’ll be much more intricate, though, in most cases. To summarize:
- Several parties engage in “production” of stale flash memory pages. Host storage stack is the major contributor, via its #1, #2, and #3 controls (Fig. 3). Embedded FTL is the only consumer, invisible to the host.
- It is the producer/consumer paradigm all over again, with the familiar dynamics that ultimately defines much of the I/O performance.
- It is the lack of communication whereby the FTL (the consumer) cannot indicate to the host: “I am about to starve”.
Open-Channel SSD: scratch the FTL!
Some people may think that proprietary FTLs circa 2016 are monolithic and heavy. That host’s multi-core horsepower and host-based storage intelligence are not properly utilized. They think that FTL’s interference results in degraded performance and shortened durability of the device under synthetic and real workloads. That FTLs cannot be easily upgraded, after all.
(There is much truth in all those statements.)
Some people therefore make the next logical step to say that embedded FTLs have no future. I’m not sure about that (see below).
Finally, there is, as far as I can see, a standalone stealth mode startup that actually does something about it. The corresponding effort is called Open-Channel SSDs, with Linux kernel-based project codenamed LightNVM.
LightNVM is an early-stage project that requires all the support they can get, and a lot of personal endurance as well, to cross the chasm. Risks include the combination of constantly improving enterprise-grade embedded FTLs on one hand, and the imminent generational shift to non-volatile byte-addressable memory.
In addition, there are current and severe bottlenecks in different parts of the software/hardware infrastructures/stacks, local filesystems including, which often makes the FTL “issue” look insignificant and reminds us yet again of a never aging Amdahl’s law and diminishing returns.
Finally, the real and almost-unlimited source of SSD performance is better parallelization, which at the time of this writing includes: 1) channel, 2) chip, 3) die, 4) lun (plane). The plane in turn contains blocks (containing pages). Reads and writes, reads and erases, writes and erases, etc. generate a variety of access conflicts when hitting the same flash chip or same die within the chip in close temporal proximity. Some of those access conflicts introduce 1ms delays or worse.
SSD manufacturers, on the other hand, constantly tweak/upgrade internal SSD architectures, making the units of parallelism more fine-grained and internal structures more dimensional (case in point: multi-level cells, 3D NAND).
And while it is totally normal and expected for the SSD controller (and its embedded FTL) to keep up with those proprietary and custom changes, it’ll be difficult to demand the same from the host driver. The latter must retain at least a semblance of vendor neutrality.
In short, there are risks. That particular LightNVM idea and that motivation is a) technical, b) debatable.
That particular LightNVM idea and that motivation is a) technical, b) debatable.
The alternative, as far as I’m concerned, would be extending the existing NVMe spec with new namespace capabilities that are easy and intuitive. One example of such a capability would be for the host and device to collaborate around the used ⇒ stale transition (Fig. 3).
So that the device could signal a message sounding like: “stop holding back unused pages”. And indicate the message’s relative urgency. And the host could take preventive steps using its “controls” (see Fig. 3).
This alternative may sound unorthodox, minimalistic, outright stupid, all of the above. The question is whether there is any adequate way to model it, measure it, and ultimately estimate.
To be continued.
