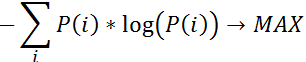
In essence, Part I of this post stipulates that distribution of states in large clusters can be approximated without making any assumptions on what kind of distribution it is in the first place.
The claim, hypothetical at this point, is that storage clusters under certain conditions must be conforming to the laws of statistical mechanics (StMch). The narrow version of the same claim relates strictly to the mathematics used in StMch.
Since the remaining part II came out pretty lengthy, heavy on math, and densely populated with equations, I’m including it here as a separate PDF.
TL;DR.
The results, I’d say, are inconclusive-but-promising. Part of being “inconclusive” is simply – not enough data, too early to say. Testing the theory on larger, 10K nodes and beyond, clusters seems like a no-brainer. However. Out of all possible whats-next ideas and steps my first preference would be to check out this theory not directly on the clustered nodes but instead on the load-balancing groups and their group-wide aggregated states..
