There’s an old trick that never quite gets old: you run a high-velocity exercise that generates a massive amount of traffic through some sort of a multi-part system, whereby some of those parts are (spectacularly) getting killed and periodically recovered.
TL;DR a simple demonstration that does exactly that (and see detailed comments inside):
| Script | Action |
|---|---|
| cp-rmnode-rebalance | taking a random node to maintenance when there’s no data redundancy |
| cp-rmnode-ec | (erasure coded content) + (immediate loss of a node) |
| cp-rmdisk | (3-way replication) + (immediate loss of a random drive) |
The scripts are self-contained and will run with any aistore instance that has at least 5 nodes, each with 3+ disks.

But when the traffic is running and the parts are getting periodically killed and recovered in a variety of realistic ways – then you would maybe want to watch it via Prometheus or Graphite/Grafana. Or, at the very least, via ais show performance – the poor man’s choice that’s always available.
for details, run:
ais show performance --help
Observability notwithstanding, the idea is always the same – to see whether the combined throughput dips at any point (it does). And by how much, how long (it depends).
There’s one (and only one) problem though: vanilla copying may sound dull and mundane. Frankly, it is totally unexciting, even when coincided with all the rebalancing/rebuilding runtime drama behind the scenes.
Copy
And so, to make it marginally more interesting – but also to increase usability – we go ahead and copy a non-existing dataset. Something like:
$ ais ls s3
No "s3://" matching buckets in the cluster. Use '--all' option to list _all_ buckets.
$ ais storage summary s3://src --all
NAME OBJECTS (cached, remote)
s3://src 0 1430
$ ais ls gs
No "gs://" matching buckets in the cluster. Use '--all' option to list _all_ buckets.
$ ais cp s3://src gs://dst --progress --refresh 3 --all
Copied objects: 277/1430 [===========>--------------------------------------------------] 19 %
Copied size: 277.00 KiB / 1.40 MiB [===========>--------------------------------------------------] 19 %
The first three commands briefly establish non-existence – the fact that there are no Amazon and Google buckets in the cluster right now.
ais storage summarycommand (and its close relativeais ls --summary) will also report whether the source is visible/accessible and will conveniently compute numbers and sizes (not shown).But because “existence” may come with all sorts of connotations the term is: presence. We say “present” or “not present” in reference to remote buckets and/or data in those buckets, whereby the latter may or may not be currently present in part or in whole.
In this case, both the source and the destination (s3://src and gs://dst, respectively) were ostensibly not present, and we just went ahead to run the copy with a progress bar and a variety of not shown list/range/prefix selections and options (see --help for details).
Transform
From here on, the immediate and fully expected question is: transformation. Namely – whether it’d be possible to transform datasets – not just copy but also apply a user-defined transformation to the source that may be (currently) stored in the AIS cluster, or maybe not or not entirely.
Something like:
$ ais etl init spec --name=my-custom-transform --from-file=my-custom-transform.yaml
followed by:
$ ais etl bucket my-custom-transform s3://src gs://dst --progress --refresh 3 --all
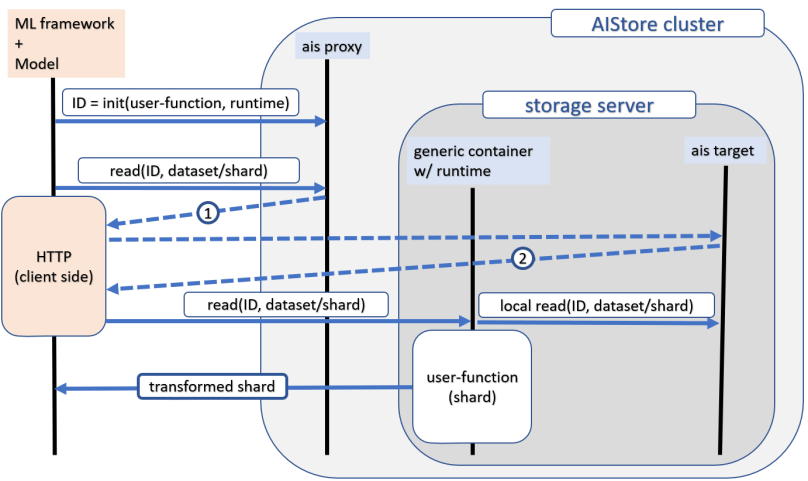
The first step deploys user containers on each clustered node. More precisely, the init-spec API call is broadcast to all target nodes; in response, each node calls K8s API to pull the corresponding image and run it locally and in parallel – but only if the container in question is not already previously deployed.
(And yes, ETL is the only aistore feature that does require Kubernetes.)
Another flavor of
ais etl initcommand isais etl init code– see--helpfor details.
That was the first step – the second is virtually identical to copying (see previous section). It’ll read remote dataset from Amazon S3, transform it, and place the result into another (e.g., Google) cloud.
As a quick aside, anything that aistore reads or writes remotely it also stores. Storing is always done in full accordance with the configured redundancy and other applicable bucket policies and – secondly – all subsequent access to the same content (that previously was remote) gets terminated inside the cluster.
Despite node and drive failures
The scripts above periodically fail and recover nodes and disks. But we could also go ahead and replace ais cp command with its ais etl counterpart – that is, replace dataset replication with dataset (offline) transformation, while leaving everything else intact.
We could do even more – select any startable job:
$ ais start <TAB-TAB>
prefetch dsort etl cleanup mirror warm-up-metadata move-bck
download lru rebalance resilver ec-encode copy-bck
and run it while simultaneously taking out nodes and disks. It’ll run and, given enough redundancy in the system, it’ll recover and will keep going.
NOTE:
The ability to recover is much more fundamental than any specific job kind that’s already supported today or will be added in the future.
Not every job is startable. In fact, majority of the supported jobs have their own dedicated API and CLI, and there are still other jobs that run only on demand.
The Upshot
The beauty of copying is in the eye of the beholder. But personally, big part of it is that there’s no need to have a client. Not that clients are bad, I’m not saying that (in fact, the opposite may be true). But there’s a certain elegance and power in running self-contained jobs that are autonomously driven by the cluster and execute at (N * disk-bandwidth) aggregated throughput, where N is the total number of clustered disks.
At the core of it, there’s the (core) process whereby all nodes, in parallel, run reading and writing threads on a per (local) disk basis, each reading thread traversing local, or soon-to-be local, part of the source dataset. Whether it’d be vanilla copying or user-defined offline transformation on steroids, the underlying iterative picture is always the same:
- read the next object using a built-in (local or remote) or etl container-provided reader
- write it using built-in (local or remote), or container-provided writer
- repeat
Parallelism and autonomy always go hand in hand. In aistore, location rules are cluster-wide universal. Given identical (versioned, protected, and replicated) cluster map and its own disposition of local disks, each node independently decides what to read and where to write it. There’s no stepping-over, no duplication, and no conflicts.
Question to maybe take offline: how to do the “nexting” when the source is remote (i.e., not present)? How to iterate a remote source without loss of parallelism?
And so, even though it ultimately boils down to iteratively calling read and write primitives, the core process appears to be infinitely flexible in its applications.
And that’s the upshot.