The Problem
In the end, the choice, like the majority of important choices, comes down to a binary: either this or that. Either you go to storage, or you don’t. Either you cache a dataset in question (and then try to operate on the cache), or make the storage itself do the “operating.”
That’s binary, and that’s the bottom line.
Of course, I’m talking about ETL workloads. Machine learning has three, and only three, distinct workloads that are known at the time of this writing. And ETL is the number one.
[ Full disclosure: the other two include model training and hyperparameter optimization ]
ETL – or you can simply say “data preprocessing” because that’s what it is (my advice, though, if I may, would be to say “ETL” as it may help institute a sense of shared values, etc.) – in short, ETL is something that is usually done prior to training.
Examples? Well, ask a random person to name a fruit, and you’ll promptly hear back “an apple.” Similarly, ask anyone to name an ETL workload, and many, maybe most, will immediately respond with “augmentation”. Which in and of itself is a shortcut for a bunch of concrete sprightly verbs: flip, rotate, scale, crop, and more.
My point? My point is, and always will be, that any model – and any deep-learning neural network, in particular – is only as good as the data you feed into it. That’s why they flip and rotate and what-not. And that’s precisely why they augment or, more specifically, extract-transform-load, raw datasets commonly used to train deep learning classifiers. Preprocess, train, and repeat. Reprocess, retrain, and compare the resulting mAP (for instance). And so on.
Moreover, deep-learning over large datasets features the proverbial 3 V’s, 4 V’s, and some will even say 5 V’s, of the Big Data. That’s a lot of V’s, by the way! Popular examples include YouTube-8M, YouTube-100M, and HowTo100M. Many more examples are also named here and here.
Very few companies can routinely compute over those (yes, extremely popular) datasets. In US, you can count them all on the fingers of one hand. They all use proprietary wherewithal. In other words, there’s a problem that exists, is singularly challenging and, for all intents and purposes, unresolved.
After all, a 100 million YouTube videos is a 100 million YouTube videos – you cannot bring them all over to your machine. You cannot easily replicate 100 million YouTube videos.
And finally – before you ask – about caching. The usual, well-respected and time-honored, approach to cache the most frequently (recently) used subset of a dataset won’t work. There’s no such thing as “the most” – every single image and every second of every single video is equally and randomly accessed by a model-in-training.
Which circles me all the way back to where I’d started: the choice. The answer at this point appears to be intuitive: storage system must operate in place and in parallel. In particular, it must run user-defined ETLs on (and by) the cluster itself.
AIS
AIStore (or AIS) is a reliable distributed storage solution that can be deployed on any commodity hardware, can run user containers and functions to transform datasets inline (on the fly) and offline, scales linearly with no limitations.
AIStore is not gen-purpose storage. Rather, it is a fully-reliable extremely-lightweight object store designed from the ground up to serve as a foundation for an integrated hyper-converged stack with a focus on deep learning.
In the 3+ years the system has been in development, it has accumulated a long list of features and capabilities, all duly noted via release notes on the corresponding GitHub pages. At this stage AIS meets most common expectations in re usability, manageability, and data protection.
AIS is an elastic cluster that grows and shrinks with no downtime and can be easily-and-quickly deployed, with or without Kubernetes, anywhere from a single machine to a bare-metal cluster of any size. For Kubernetes-based deployments, there’s a whole separate repository that contains AIS deployment playbooks, Helm charts, and Kubernetes Operator.
The system features data protection and self-healing capabilities that users come to normally expect nowadays. But it can also be used as fast ad-hoc cache in front of the five (so far) supported backends, with AIS itself being the number six.
The picture below illustrates inline transformation, whereby each shard from a given distributed dataset gets transformed in-place by a user-provided function. It goes as follows:
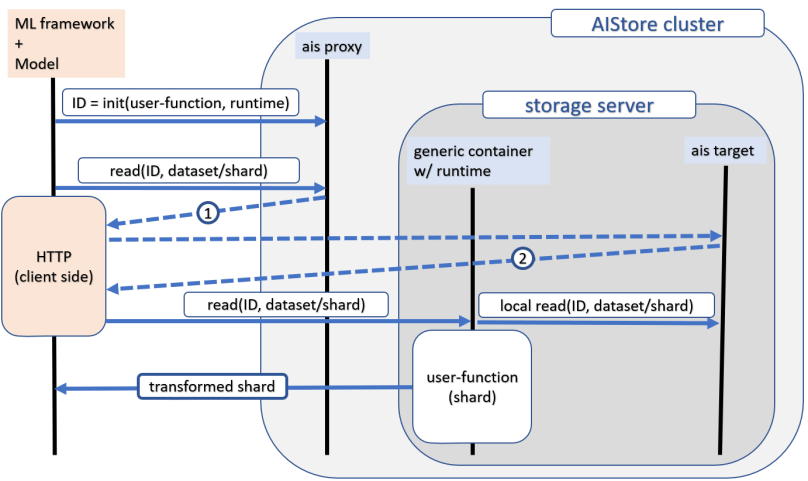
- A user initiates custom transformation by executing documented REST APIs and providing either a docker image (that we can pull) or a transforming function that we further run using one of the pre-built runtimes;
- The API call triggers simultaneous deployment of multiple ETL containers (i.e., K8s pods) across the entire cluster: one container alongside each AIS target;
- Client-side application (e.g., PyTorch or TensorFlow-based training model) starts randomly reading sharded samples from a given dataset;
- Each read request:
- quickly bounces off via HTTP redirect – first, of an AIS proxy (gateway) and, second, of AIS target – reaching its designated destination – the ETL container that happens to be “local” to the requested shard, after which:
- the container performs local reading of the shard, applies user-provided transforming function to the latter, and, finally, responds inline to the original read request with the transformed bytes.
Supported
The sequence above is one of the many supported permutations that also include:
- User-defined transformation via:
- ETL container that runs HTTP server and implements one of the supported APIs, or
- user function that we run ourselves given one of the supported runtimes;
- AIS target <=> ETL container communication via:
- HTTP redirect – as shown in the picture, or
- AIS target performing the read and “pushing” read bytes into locally deployed ETL to further get back transformed bytes and respond to the original request.
And more. Offline – input dataset => output dataset – transformation is also available. A reverse-proxy option is supported as well, although not recommended.
Remark
In the end, the choice, like so many important choices we make, is binary. But it is good to know what can be done and what’s already actually working.
