
The Transmission Control Protocol (TCP) was first proposed in 1974, first standardized in 1981, first implemented in 1984, and published in 1988. This 1988 paper, by Van Jacobson, for the first time described the TCP’s AIMD policy to control congestion. But that was then. Today, the protocol carries the lion’s share of all Internet traffic, which, according to Cisco, keeps snowballing at a healthy 22% CAGR.
TCP, however, is not perfect. “Although there is no immediate crisis, TCP’s AIMD algorithm is showing its limits in a number of areas”, says the responsible IETF group. Notwithstanding the imperfections, the protocol is, in effect, hardwired into all routers and middleboxes produced since 1984, which in part explains its ubiquity and dominance. But that’s not the point.
The point is – congestion. Or rather, congestion avoidance. At best – prevention, at least – control. Starting from its very first AIMD implementation, much of what TCP does is taking care of congestion. The difference between numerous existing TCP flavors (and much more numerous suggested improvements) boils down to variations in a single formula that computes TCP sending rate as a function of loss events and roundtrip times (RTT).
Of course, there is also a slow start and a receiver’s advertised window but that’s, again, beside the point…
The point is that the congested picture always looks the same: Time t1 – everything is cool, t2 – a spike, a storm, a flood, a “Houston, we have a problem”, t3 – back to cool again.
Time t1 – everything is cool, t2 – a spike, a storm, a flood, a “Houston, we have a problem”, t3 – back to cool again.
What we always want – for ourselves and for our apps – is this:![]() But instead, it is often like this:
But instead, it is often like this: Or worse.
Or worse.
Fundamentally, “congestion” (the word) relates to shortage of any shared resource. In networking, it’s just shorthand for a limited resource (a bunch of interconnected “pipes”) shared by multiple “users” (TCP flows).
When a) the resource is limited (it always is!) and when b) resource users are dynamic, numerous, bursty, short-long-lived, and all greedy to grab a share – then we would always have a c) congestion situation. Potentially. And likely. Especially taking into account that TCP flows are mutually-independent, scheduling-wise.
Especially taking into account that TCP flows are mutually-independent, scheduling-wise.
Therefore, from the pure-common-sense perspective, there must be only two ways to not have congestion:
- better algorithms (that would either do a better job at scheduling TCP flows, or that would support some form of coordinated QoS), or
- bigger pipes (as in: overprovisioning)
Logically, there seem to be no third alternative. That is, unless…
Unless we consider the following chain of logic. TCP gets congested – why? Because the pipe is limited and shared. But why then the congestion becomes a what’s called an exceptional event? Why can’t we simply ignore it? Because the two communicating endpoints expect the data to be delivered there and acknowledged now.
(Think about this for a second before reading the next sentence.)
The idea would be to find (invent, or reinvent) an app that would break with this there-and-now paradigm. It would, instead, start communicating at time t1: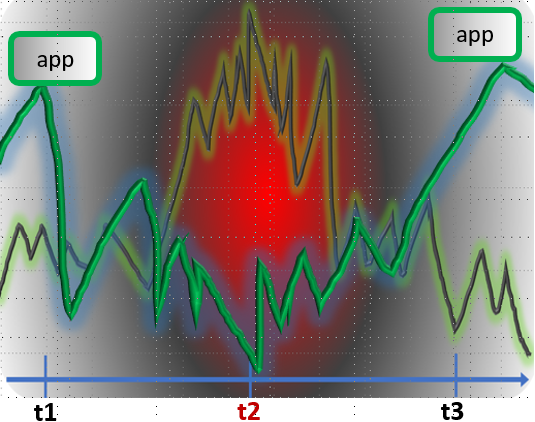 When it probably would – prior to t2 – send and receive some data. And then, more data at around and after t3. Which is fine, as long as the app in question could function without this data altogether and maybe (preferably) take advantage of having any of it, if available.
When it probably would – prior to t2 – send and receive some data. And then, more data at around and after t3. Which is fine, as long as the app in question could function without this data altogether and maybe (preferably) take advantage of having any of it, if available.
The behavior that we’d be looking for is called, of course, caching. There are, of course, a ton of networking apps that do cache. There are also a few technical details to flush out before any of it gets anywhere close to being useful (which would be outside the scope of this post).
What’s important, though, is breaking with the there-and-now paradigm, so entrenched that it’s almost hardwired into our brains. Like TCP – into middleboxes.
PS.
Which reminds of a Sutton’s law: when diagnosing, one should first consider the obvious. Why a bank robber robs banks? Because that’s where the money is. Why should you communicate at non-congested times? Because that’s when you can…
