What’s in the name
It is difficult to say when exactly the “hyper” prefix was the first time attached to “converged” infrastructure. Hyper-convergence, also known as hyperconvergence, ultimately means a fairly simple thing: running user VMs on virtualized and clustered storage appliances. The latter in turn collaborate behind the scenes to a) pool combined local storage resources to further b) share the resulting storage pool between all (or some) VMs and c) scale-out the VM’s generated workload.
That’s the definition, with an emphasis on storage. A bit of a mouthful but ultimately simple if one just pays attention to a) and b) and c) above. Players in the space include Nutanix, SimpliVity and a few other companies on one hand, and VMware on another.
Virtualized storage appliance that does storage pooling, sharing and scaling is a piece of software, often dubbed “storage controller” that is often (but not always) packaged as a separate VM on each clustered hypervisor. Inquisitive reader will note that, unlike Nutanix et al, VMware’s VSAN is part and parcel of the ESXi’s own operating system, an observation that only reinforces the point or rather the question, which is:
True Scale-Out
True scale-out always has been and will likely remain the top challenge. What’s a “true scale-out” – as opposed to limited scale-out or apparent scale-out? Well, true scale-out is the capability to scale close to linearly under all workloads. In other words, it’s the unconditional capability to scale: add new node to an existing cluster of N nodes, and you are supposed to run approximately (N + 1)/N faster. Workloads must not even be mentioned with respect to the scale-out capabilities, and if they are, there must be no fine print..
Needless to say, developers myself including will use every trick in the book and beyond, to first and foremost optimize workloads that represent (at the time of development) one or two or a few major use cases. Many of those tricks and techniques are known for decades and generally relate to the art (or rather, the craft) of building distributed storage systems.
(Note: speaking of distributed storage systems, a big and out-of-scope topic in and of itself, I will cover some of the aspects in presentation for the upcoming SNIA SDC 2015 and will post the link here, with maybe some excerpts as well)
But there’s one point, one difference that places hyperconverged clusters apart from the distributed storage legacy: locality of the clients. With advent of hyperconverged solutions and products the term local acquired a whole new dimension, simply due to the fact that those VMs that generate user traffic – each and every one of them runs locally as far as (almost) exactly 1/Nth of the storage resources.
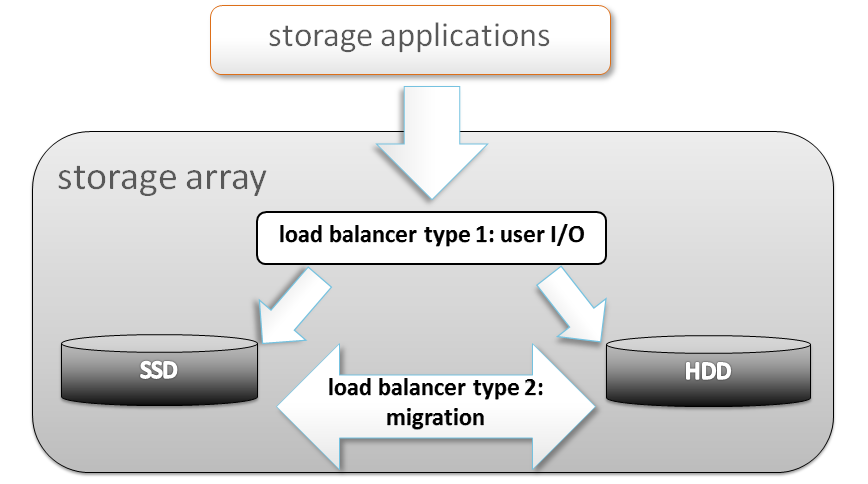
Conceptually in that sense, clustered volatile and persistent memories are stacked as follows, with the top tier represented by local hypervisor’s RAM and the lowest tier – remote hard drives.

(Note: within local-rack vs. inter-rack tiering, as well as, for instance, utilizing remote RAM to store copies or stripes of hot data, and a few other possible tiering designations are intentionally simplified out as sophisticated and not very typical today)
Adding a new node to hyperconverged cluster and placing a new bunch of VMs on it may appear to scale if much of the new I/O traffic remains local to this new node, utilizing its new RAM, its new drives and its new CPUs. De-staging (the picture above) would typically/optimally translate as gradual propagation of copies of aggregated and compressed fairly large in size logical blocks across conceptual layers, with neighboring node’s SSDs utilized first..
But then again, we’d be talking about an apparent and limited scale-out that performs marginally better but costs inevitably much more, CapEx and OpEx wise, than any run-of-the-mill virtual cluster.
Local Squared
Great number, likely a substantial majority of existing apps keep using legacy non-clustered filesystems and databases that utilize non-shared LUNs. When deploying those apps inside VMs, system administrators simply provision one, two, several vdisks/vmdks for exclusive (read: local, non-shared) usage by the VM itself.
Here again the aforementioned aspect of hyperconvergent locality comes out in force: a vendor will make double sure to keep at least caching and write-logging “parts” of those vdisks very local to the hypervisor that runs the corresponding VM. Rest assured, best of the vendors will apply the same “local-first” policy to the clustered metadata as well..
Scenarios: probabilistic, administrative and cumulative
The idea therefore is to come up with workloads that break (the indeed, highly motivated) locality of generated I/Os by forcing local hypervisor to write (to) and read from remote nodes. And not in a deferred way but inline, as part of the actual (application I/O ⇔ persistent storage) datapath with client that issued the I/Os waiting for completions on the other side of the I/O pipeline..
An immediate methodological question would be: Why? Why do we need do run some abstracted workload that may in no way be similar to one produced by the intended apps? There are at least 3 answers to this one that I’ll denote as, say, probabilistic, administrative and cumulative.
Real-life workloads are probabilistic in nature: the resulting throughput, latencies and IOPS are distributed around their respective averages in complex ways which, outside pristine lab environments, is very difficult to extrapolate with bell curves. Most of the time a said workload may actively be utilizing a rather small percentage of total clustered capacity (the term for this is “working set” – a portion of total data accessed by the app at any given time). Most of the time – but not all the time: one typical issue for users and administrators is that a variety of out-of-bounds situations requires many hours, days or even weeks of continuous operation to present itself. Other examples include bursts of writes or reads (or both) that are two or more times longer than a typical burst, etc.
Administrative maintenance operations do further exacerbate. For example, deletion of older VM images that must happen from time to time on any virtualized infrastructure – when this seemingly innocuous procedure is carried out concurrently with user traffic, long-time cold data and metadata sprawled across the entire cluster suddenly comes into play – in force.
Cumulative-type complications further include fragmentation of logical and physical storage spaces that is inevitable after multiple delete and rewrite operations (of the user data, snapshots, and user VMs), as well as gradual accumulation of sector errors. This in turn will gradually increase ratios of one or two or may be both of the otherwise unlikely scenarios: random access when reading and writing sequential data, and read-modify-writes of the metadata responsible to track the fragmented “holes”.
Related to the above would be the compression+rewrite scenario: compression of aggregated sequentially written logical blocks whereby the application updates, possibly sequentially as well, its (application-level) smaller-size blocks thus forcing storage subsystem to read-modify-write (or more exactly, read-decompress-modify-compress and finally write) yet again.
Critical Litmus Test: 3 simple guidelines
The question therefore is, how to quickly exercise the most critical parts of the storage subsystem for true scale-out capability. Long and short of it boils down to the following simple rules:
1. Block size
The block size must be small, preferably 4K or 8K. The cluster that scales under application-generated small blocks will likely scale under medium (32K to 64K, some say 128K) and large blocks (1M and beyond) as well. On the other hand, a failure to scale under small blocks will likely manifest future problems in handling some or all of the scenarios mentioned above (and some that are not mentioned as well).
On the third hand, a demonstrated scale-out capability to operate on medium and large blocks does not reflect on the chances to handle tougher scenarios – in fact, there’d be no correlation whatsoever.
2. Working set
The working set must be set to at least 60% of the total clustered capacity, and at least 5 times greater than RAM of any given node. That is, the MAX(60% of total, 5x RAM).
Reason for this is that it is important to exercise the cluster under workloads that explicitly prevent “localizations” of their respective working sets.
3. I/O profile
Finally, random asynchronous I/Os with 100%, 80/20% and 50/50% of write/read ratios respectively, carrying pseudo-random payload that is either not compressible at all or compressible at or below 1.6 ratio.
That’ll do it, in combination with vdbench or any other popular micro-benchmark capable to generate pedal-to-the-metal type load that follows these 3 simple rules. Make sure not to bottleneck on CPUs and/or network links of course, and run it for at least couple hours on at least two clustered sizes, one representing a scaled-out version of the other..
Final Remarks
Stating maybe the obvious now – when benchmarking, it is important to compare apples-to-apples: same vendor, same hardware, same software, same workload scaled out proportionally – two different clustered sizes, e.g. 3 nodes and 6 nodes, for starters.
The simple fact that a given hyperconverged hardware utilizes latest-greatest SSDs may contribute to the performance that will look very good, in isolation. In comparison and under stress (above) – maybe not so much.
One way to view the current crop of hyperconverged products: a fusion of distributed storage, on one hand and hybrid/tiered storage, on another. This “fusion” is always custom, often ingenious, with tiering hidden inside to help deliver performance and assist (put it this way) scaling out..